Plotting in Python¶
There are several popular plotting libaries:
matplotlib: low level plotting tools
seaborn: high level plotting with opinionated defaults
ggplot: plotting based on the ggplot library in R.
Plus pandas has a plot method
Pandas and seaborn use matplotlib under the hood.
Seaborn and ggplot both assume the data is set up as a DataFrame. Getting started with seaborn is the simplest, so we’ll use that.
Figure and axis level plots¶
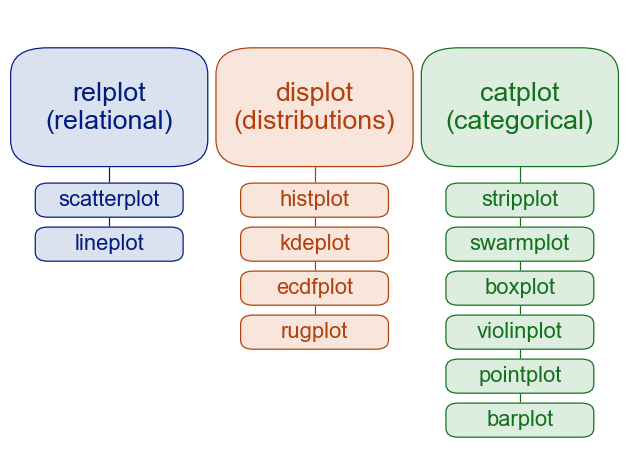
add the image to your notebook with the following:
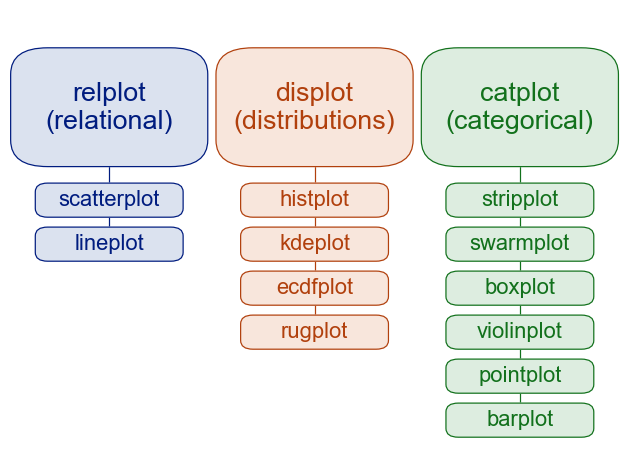Anatomy of a figure¶
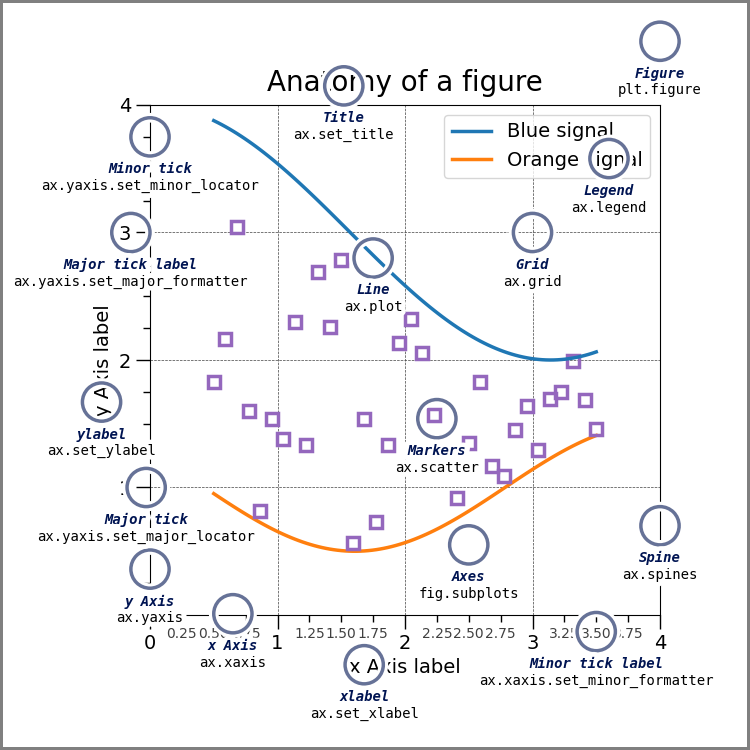
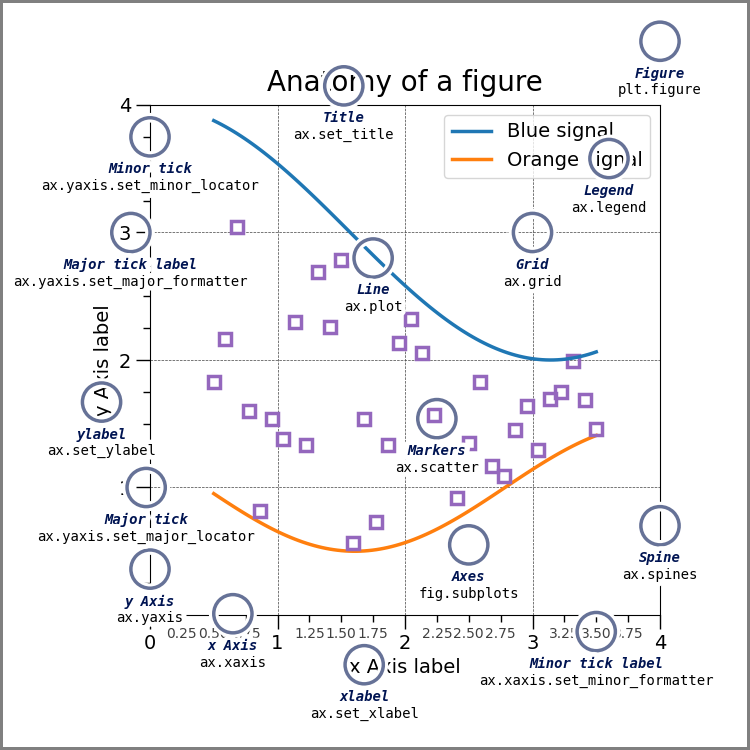
*this was drawn with code
add the image to your notebook with the following:
we will load pandas and seaborn
import pandas as pd
import seaborn as snsand we will use a new dataset for today with more rows:
arabica_data_url = 'https://raw.githubusercontent.com/jldbc/coffee-quality-database/master/data/arabica_data_cleaned.csv'then load it in as normal
coffee_df = pd.read_csv(arabica_data_url,index_col=0)since it’s new, we will take a quick look with head
coffee_df.head()and then see the shape to know how big it is before we start working
coffee_df.shape(1311, 43)coffee_df['Flavor'].describe()count 1311.000000
mean 7.518070
std 0.399979
min 0.000000
25% 7.330000
50% 7.580000
75% 7.750000
max 8.830000
Name: Flavor, dtype: float64Distribution Plots¶
sns.displot(data=coffee_df,x='Flavor')<seaborn.axisgrid.FacetGrid at 0x7f1ca8bedf70>
sns.displot(data=coffee_df,x='Flavor',kind='kde')<seaborn.axisgrid.FacetGrid at 0x7f1ca9944260>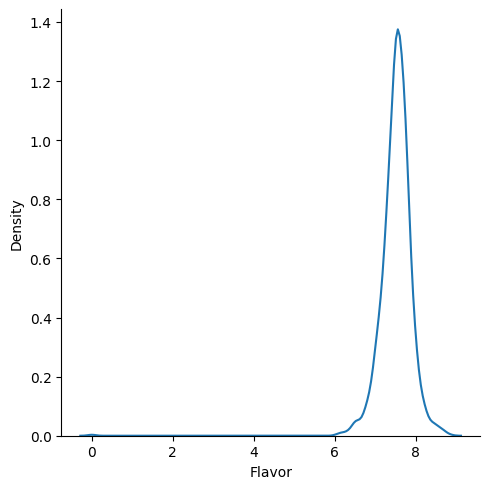
sns.displot(data=coffee_df,x='Flavor',kind='kde',hue='Color')<seaborn.axisgrid.FacetGrid at 0x7f1ca8168e60>
Relation Plots¶
sns.relplot(data=coffee_df, x='Flavor',y='Balance')<seaborn.axisgrid.FacetGrid at 0x7f1d003dfce0>
sns.relplot(data=coffee_df, x='Flavor',y='Balance',hue='Color')<seaborn.axisgrid.FacetGrid at 0x7f1ca8098050>
coffee_df.columnsIndex(['Species', 'Owner', 'Country.of.Origin', 'Farm.Name', 'Lot.Number',
'Mill', 'ICO.Number', 'Company', 'Altitude', 'Region', 'Producer',
'Number.of.Bags', 'Bag.Weight', 'In.Country.Partner', 'Harvest.Year',
'Grading.Date', 'Owner.1', 'Variety', 'Processing.Method', 'Aroma',
'Flavor', 'Aftertaste', 'Acidity', 'Body', 'Balance', 'Uniformity',
'Clean.Cup', 'Sweetness', 'Cupper.Points', 'Total.Cup.Points',
'Moisture', 'Category.One.Defects', 'Quakers', 'Color',
'Category.Two.Defects', 'Expiration', 'Certification.Body',
'Certification.Address', 'Certification.Contact', 'unit_of_measurement',
'altitude_low_meters', 'altitude_high_meters', 'altitude_mean_meters'],
dtype='object')sns.relplot(data=coffee_df, x='Flavor',y='Balance',hue='Color',col='Country.of.Origin',col_wrap=4)/home/runner/.local/lib/python3.12/site-packages/seaborn/axisgrid.py:854: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(*plot_args, **plot_kwargs)
/home/runner/.local/lib/python3.12/site-packages/seaborn/axisgrid.py:854: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(*plot_args, **plot_kwargs)
<seaborn.axisgrid.FacetGrid at 0x7f1ca810e8d0>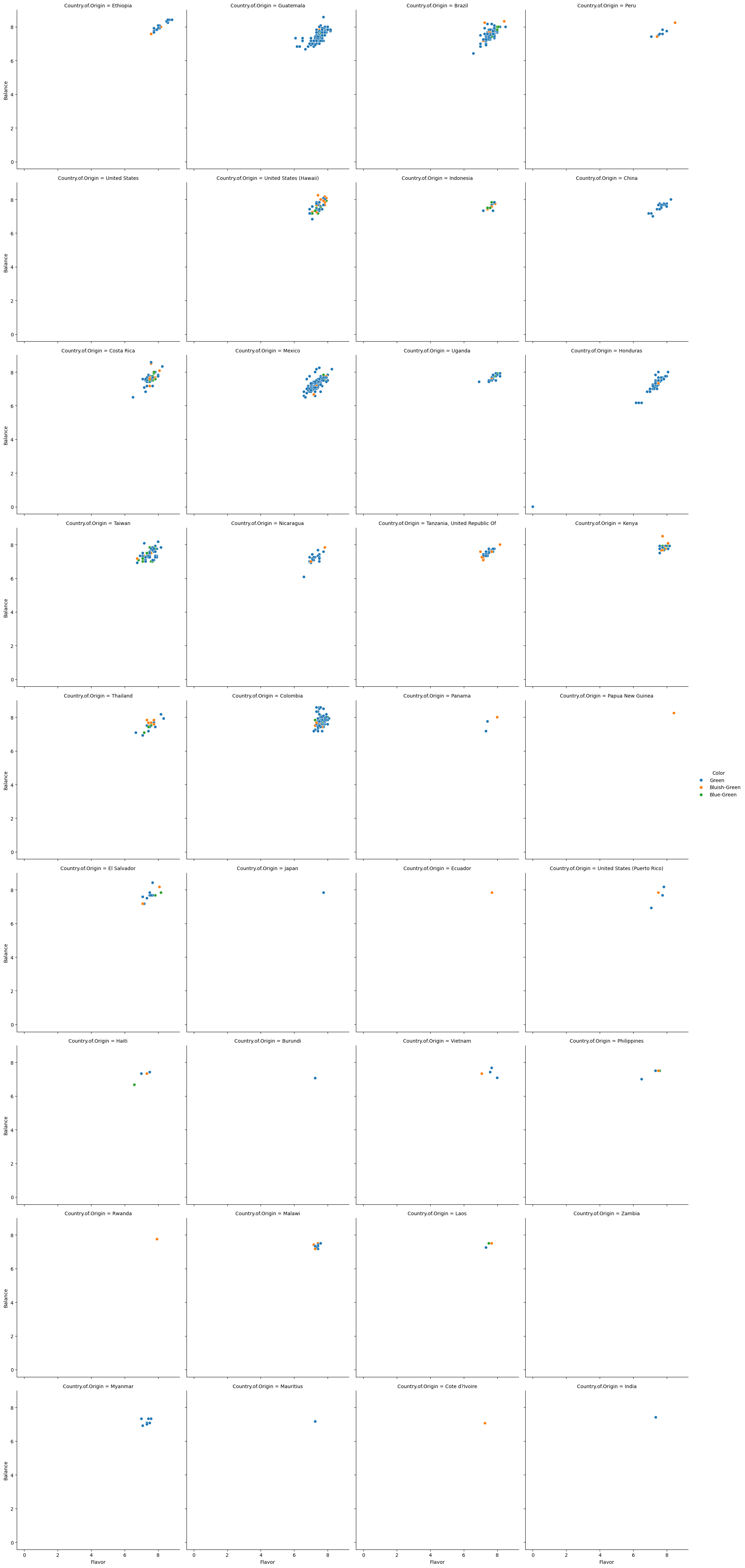
Categorical Plots¶
By default a catplot is a stripplot
sns.catplot(coffee_df, y='Number.of.Bags', x='Country.of.Origin')<seaborn.axisgrid.FacetGrid at 0x7f1ca811b1a0>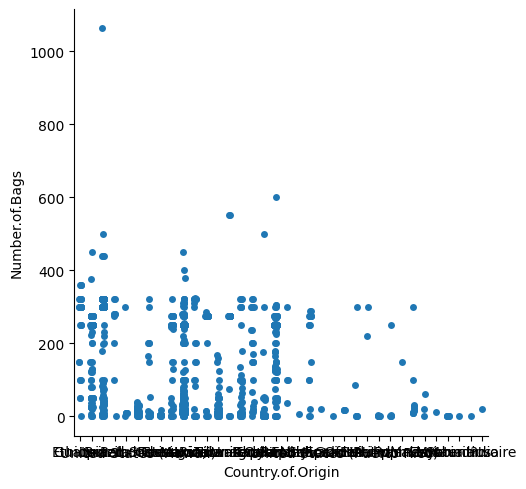
For this data, this is really hard to understand, let’s change to a bar version
sns.catplot(coffee_df, y='Number.of.Bags', x='Country.of.Origin',kind='bar')<seaborn.axisgrid.FacetGrid at 0x7f1ca831b6b0>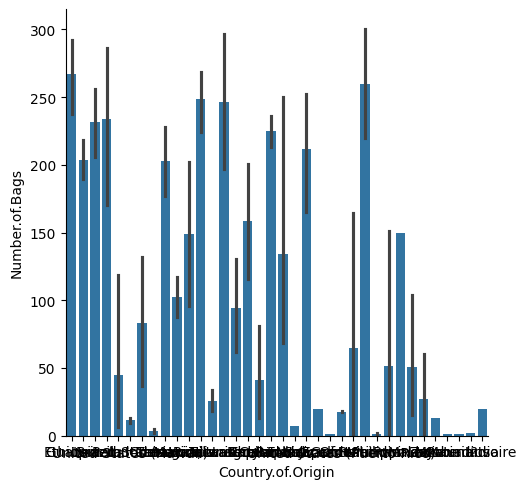
Here, it takes the mean for each country and that is the bar height and the line is the std for each country.
It uses logic similar to:
coffee_df.groupby('Country.of.Origin')['Number.of.Bags'].describe()Filtering with isin¶
First we can find the top countries, we noticed that the value_counts are sorted so we take the first 10
top_countries = coffee_df['Country.of.Origin'].value_counts()[:10].index
top_countriesIndex(['Mexico', 'Colombia', 'Guatemala', 'Brazil', 'Taiwan',
'United States (Hawaii)', 'Honduras', 'Costa Rica', 'Ethiopia',
'Tanzania, United Republic Of'],
dtype='object', name='Country.of.Origin')we can use that to filter the original DataFrame. To do this, we use isin to check each element in the 'Country.of.Origin' column is in that list.
coffee_df['Country.of.Origin'].isin(top_countries)1 True
2 True
3 True
4 True
5 True
...
1307 True
1308 False
1309 False
1310 True
1312 True
Name: Country.of.Origin, Length: 1311, dtype: boolThis is roughly equivalent to:
[country in top_countries for country in coffee_df['Country.of.Origin'] ][True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
False,
False,
True,
True,
False,
False,
True,
False,
True,
False,
True,
True,
False,
True,
True,
True,
False,
True,
True,
False,
True,
True,
True,
True,
False,
True,
True,
True,
False,
False,
True,
True,
True,
False,
True,
False,
True,
False,
False,
True,
True,
True,
False,
True,
False,
True,
True,
True,
True,
False,
False,
False,
False,
True,
False,
False,
True,
False,
True,
True,
False,
True,
True,
False,
False,
True,
True,
True,
False,
False,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
False,
True,
True,
True,
False,
False,
True,
False,
False,
False,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
False,
True,
False,
True,
True,
False,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
False,
False,
True,
True,
False,
True,
False,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
False,
True,
True,
False,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
False,
False,
False,
False,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
False,
False,
True,
False,
True,
True,
True,
True,
False,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
False,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
False,
True,
True,
False,
False,
False,
True,
True,
False,
False,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
False,
False,
True,
False,
True,
True,
True,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
False,
False,
True,
False,
True,
True,
True,
True,
False,
False,
True,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
False,
True,
True,
False,
False,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
False,
True,
True,
False,
True,
True,
True,
False,
False,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
False,
True,
False,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
False,
False,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
False,
True,
False,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
False,
False,
True,
True,
False,
True,
True,
True,
False,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
True,
False,
False,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
True,
True,
False,
True,
True,
True,
True,
False,
False,
True,
False,
True,
True,
True,
True,
True,
True,
True,
True,
False,
False,
True,
True,
False,
True,
True,
True,
True,
True,
True,
False,
...]except this builds a list and the pandas way makes a pd.Series object. The Python in operator is really helpful to know and pandas offers us an isin method to get that type of pattern.
In a more basic programming format this process would be two separate loops worth of work.
c_in = []
# iterate over the country of each rating
for country in coffee_df['Country.of.Origin']:
# make a false temp value
cur_search = False
# iterate over top countries
for tc in top_countries:
# flip the value if the current top & rating cofee match
if tc==country:
cur_search = True
# save the result of the search
c_in.append(cur_search)With that list of booleans, we can then mask the original DataFrame. This keeps only the value where the inner quantity is True
top_coffee_df = coffee_df[coffee_df['Country.of.Origin'].isin(top_countries)]
top_coffee_df.head(1)And now we can plot from that new dataframe
sns.catplot(data =top_coffee_df,x='Country.of.Origin',y='Number.of.Bags', aspect=3)<seaborn.axisgrid.FacetGrid at 0x7f1ca0c10e60>
Now with the stripplot we can see that it puts a point for each coffee (row in the dataframe) and adds random jitter so they do not all overlap since the x values are the countries which are discrete
Install some extra tools¶
pip install jupytext mystmdVariable types and data types¶
Related but not the same.
Data types are literal, related to the representation in the computer.
ther can be int16, int32, int64
We can also have mathematical types of numbers
Integers can be positive, 0, or negative.
Reals are continuous, infinite possibilities.
Variable types are about the meaning in a conceptual sense.
categorical (can take a discrete number of values, could be used to group data, could be a string or integer; unordered)
continuous (can take on any possible value, always a number)
binary (like data type boolean, but could be represented as yes/no, true/false, or 1/0, could be categorical also, but often makes sense to calculate rates)
ordinal (ordered, but appropriately categorical)
we’ll focus on the first two most of the time. Some values that are technically only integers range high enough that we treat them more like continuous most of the time.
Grading Review¶
We discussed the grading
Assignment 1 Q&A¶
For this assignment if you atted Friday office hours you can get an automatic extension, but going forward the policy will apply.
Questions After Class¶
Why did you use the . in between spaces for country of origin?¶
because that is how the column is actually named.
We are picking out the column name, not just describing it.
coffee_df.columnsIndex(['Species', 'Owner', 'Country.of.Origin', 'Farm.Name', 'Lot.Number',
'Mill', 'ICO.Number', 'Company', 'Altitude', 'Region', 'Producer',
'Number.of.Bags', 'Bag.Weight', 'In.Country.Partner', 'Harvest.Year',
'Grading.Date', 'Owner.1', 'Variety', 'Processing.Method', 'Aroma',
'Flavor', 'Aftertaste', 'Acidity', 'Body', 'Balance', 'Uniformity',
'Clean.Cup', 'Sweetness', 'Cupper.Points', 'Total.Cup.Points',
'Moisture', 'Category.One.Defects', 'Quakers', 'Color',
'Category.Two.Defects', 'Expiration', 'Certification.Body',
'Certification.Address', 'Certification.Contact', 'unit_of_measurement',
'altitude_low_meters', 'altitude_high_meters', 'altitude_mean_meters'],
dtype='object')If we pick any of those values we get that column:
from numpy.random import choice
random_col = choice(coffee_df.columns)
coffee_df[random_col].head()1 metad agricultural developmet plc
2 metad agricultural developmet plc
3 NaN
4 yidnekachew debessa coffee plantation
5 metad agricultural developmet plc
Name: Company, dtype: objector any other one
random_col = choice(coffee_df.columns)
coffee_df[random_col].head()1 10.0
2 10.0
3 10.0
4 10.0
5 10.0
Name: Sweetness, dtype: float64typo_col = 'country of origin'
coffee_df[typo_col].head()---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File ~/.local/lib/python3.12/site-packages/pandas/core/indexes/base.py:3812, in Index.get_loc(self, key)
3811 try:
-> 3812 return self._engine.get_loc(casted_key)
3813 except KeyError as err:
File pandas/_libs/index.pyx:167, in pandas._libs.index.IndexEngine.get_loc()
File pandas/_libs/index.pyx:196, in pandas._libs.index.IndexEngine.get_loc()
File pandas/_libs/hashtable_class_helper.pxi:7088, in pandas._libs.hashtable.PyObjectHashTable.get_item()
File pandas/_libs/hashtable_class_helper.pxi:7096, in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'country of origin'
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
Cell In[26], line 2
1 typo_col = 'country of origin'
----> 2 coffee_df[typo_col].head()
File ~/.local/lib/python3.12/site-packages/pandas/core/frame.py:4113, in DataFrame.__getitem__(self, key)
4111 if self.columns.nlevels > 1:
4112 return self._getitem_multilevel(key)
-> 4113 indexer = self.columns.get_loc(key)
4114 if is_integer(indexer):
4115 indexer = [indexer]
File ~/.local/lib/python3.12/site-packages/pandas/core/indexes/base.py:3819, in Index.get_loc(self, key)
3814 if isinstance(casted_key, slice) or (
3815 isinstance(casted_key, abc.Iterable)
3816 and any(isinstance(x, slice) for x in casted_key)
3817 ):
3818 raise InvalidIndexError(key)
-> 3819 raise KeyError(key) from err
3820 except TypeError:
3821 # If we have a listlike key, _check_indexing_error will raise
3822 # InvalidIndexError. Otherwise we fall through and re-raise
3823 # the TypeError.
3824 self._check_indexing_error(key)
KeyError: 'country of origin'this is because country of origin is not a column in the dataset
typo_col in coffee_df.columnsFalseis the random jitter for same number inclusive or exclude (can the dots overlap completely if unlucky)¶
it is random, so they can overlap, but it would be exceedingly unlucky for more than two to cmopletely overlap