
24. Classifying Text#
from sklearn.feature_extraction import text
from sklearn.metrics.pairwise import euclidean_distances
from sklearn import datasets
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.naive_bayes import MultinomialNB, GaussianNB
from sklearn.model_selection import train_test_split
# edited so I can reuse these later
selected_categories = ['comp.graphics','sci.crypt']
ng_X,ng_y = datasets.fetch_20newsgroups(categories =selected_categories,
return_X_y = True)
from sklearn.metrics import confusion_matrix
24.1. review of count representation#
ex_vocab = ['and', 'are', 'cat', 'cats', 'dogs', 'pets', 'popular', 'videos']
sample = 'Cats and dogs are pets'
rep = [1, 1, 0, 1, 1, 1, 0, 0]
24.2. News Data#
Lables are the topic of the article 0 = computer graphics, 1 = cyrptography.
type(ng_X)
list
len(ng_X)
1179
the X is he actual text
print(ng_X[0])
From: robert@cpuserver.acsc.com (Robert Grant)
Subject: Virtual Reality for X on the CHEAP!
Organization: USCACSC, Los Angeles
Lines: 187
Distribution: world
Reply-To: robert@cpuserver.acsc.com (Robert Grant)
NNTP-Posting-Host: cpuserver.acsc.com
Hi everyone,
I thought that some people may be interested in my VR
software on these groups:
*******Announcing the release of Multiverse-1.0.2*******
Multiverse is a multi-user, non-immersive, X-Windows based Virtual Reality
system, primarily focused on entertainment/research.
Features:
Client-Server based model, using Berkeley Sockets.
No limit to the number of users (apart from performance).
Generic clients.
Customizable servers.
Hierachical Objects (allowing attachment of cameras and light sources).
Multiple light sources (ambient, point and spot).
Objects can have extension code, to handle unique functionality, easily
attached.
Functionality:
Client:
The client is built around a 'fast' render loop. Basically it changes things
when told to by the server and then renders an image from the user's
viewpoint. It also provides the server with information about the user's
actions - which can then be communicated to other clients and therefore to
other users.
The client is designed to be generic - in other words you don't need to
develop a new client when you want to enter a new world. This means that
resources can be spent on enhancing the client software rather than adapting
it. The adaptations, as will be explained in a moment, occur in the servers.
This release of the client software supports the following functionality:
o Hierarchical Objects (with associated addressing)
o Multiple Light Sources and Types (Ambient, Point and Spot)
o User Interface Panels
o Colour Polygonal Rendering with Phong Shading (optional wireframe for
faster frame rates)
o Mouse and Keyboard Input
(Some people may be disappointed that this software doesn't support the
PowerGlove as an input device - this is not because it can't, but because
I don't have one! This will, however, be one of the first enhancements!)
Server(s):
This is where customization can take place. The following basic support is
provided in this release for potential world server developers:
o Transparent Client Management
o Client Message Handling
This may not sound like much, but it takes away the headache of
accepting and
terminating clients and receiving messages from them - the
application writer
can work with the assumption that things are happening locally.
Things get more interesting in the object extension functionality. This is
what is provided to allow you to animate your objects:
o Server Selectable Extension Installation:
What this means is that you can decide which objects have extended
functionality in your world. Basically you call the extension
initialisers you want.
o Event Handler Registration:
When you develop extensions for an object you basically write callback
functions for the events that you want the object to respond to.
(Current events supported: INIT, MOVE, CHANGE, COLLIDE & TERMINATE)
o Collision Detection Registration:
If you want your object to respond to collision events just provide
some basic information to the collision detection management software.
Your callback will be activated when a collision occurs.
This software is kept separate from the worldServer applications because
the application developer wants to build a library of extended objects
from which to choose.
The following is all you need to make a World Server application:
o Provide an initWorld function:
This is where you choose what object extensions will be supported, plus
any initialization you want to do.
o Provide a positionObject function:
This is where you determine where to place a new client.
o Provide an installWorldObjects function:
This is where you load the world (.wld) file for a new client.
o Provide a getWorldType function:
This is where you tell a new client what persona they should have.
o Provide an animateWorld function:
This is where you can go wild! At a minimum you should let the objects
move (by calling a move function) and let the server sleep for a bit
(to avoid outrunning the clients).
That's all there is to it! And to prove it here are the line counts for the
three world servers I've provided:
generic - 81 lines
dactyl - 270 lines (more complicated collision detection due to the
stairs! Will probably be improved with future
versions)
dogfight - 72 lines
Location:
This software is located at the following site:
ftp.u.washington.edu
Directory:
pub/virtual-worlds
File:
multiverse-1.0.2.tar.Z
Futures:
Client:
o Texture mapping.
o More realistic rendering: i.e. Z-Buffering (or similar), Gouraud shading
o HMD support.
o Etc, etc....
Server:
o Physical Modelling (gravity, friction etc).
o Enhanced Object Management/Interaction
o Etc, etc....
Both:
o Improved Comms!!!
I hope this provides people with a good understanding of the Multiverse
software,
unfortunately it comes with practically zero documentation, and I'm not sure
whether that will ever be able to be rectified! :-(
I hope people enjoy this software and that it is useful in our explorations of
the Virtual Universe - I've certainly found fascinating developing it, and I
would *LOVE* to add support for the PowerGlove...and an HMD :-)!!
Finally one major disclaimer:
This is totally amateur code. By that I mean there is no support for this code
other than what I, out the kindness of my heart, or you, out of pure
desperation, provide. I cannot be held responsible for anything good or bad
that may happen through the use of this code - USE IT AT YOUR OWN RISK!
Disclaimer over!
Of course if you love it, I would like to here from you. And anyone with
POSITIVE contributions/criticisms is also encouraged to contact me. Anyone who
hates it: > /dev/null!
************************************************************************
*********
And if anyone wants to let me do this for a living: you know where to
write :-)!
************************************************************************
*********
Thanks,
Robert.
robert@acsc.com
^^^^^^^^^^^^^^^
ng_y[:3]
array([0, 0, 1])
24.3. Count Vectorization#
We’re going to instantiate the object and fit it two the whole dataset.
count_vec = text.CountVectorizer()
ng_vec = count_vec.fit_transform(ng_X)
ng_vec.shape
(1179, 24257)
type(ng_vec)
scipy.sparse._csr.csr_matrix
Now get a classifier ready:
clf = MultinomialNB()
THen train/test split:
ng_vec_train, ng_vec_test, ng_y_train, ng_y_test = train_test_split(ng_vec,ng_y)
clf.fit(ng_vec_train,ng_y_train).score(ng_vec_test,ng_y_test)
0.9830508474576272
clf.__dict__
{'alpha': 1.0,
'fit_prior': True,
'class_prior': None,
'force_alpha': 'warn',
'n_features_in_': 24257,
'classes_': array([0, 1]),
'class_count_': array([438., 446.]),
'feature_count_': array([[30., 11., 0., ..., 0., 0., 0.],
[26., 8., 2., ..., 1., 1., 1.]]),
'feature_log_prob_': array([[ -8.37071195, -9.31979251, -11.80469916, ..., -11.80469916,
-11.80469916, -11.80469916],
[ -8.84621446, -9.94482675, -11.04343904, ..., -11.44890414,
-11.44890414, -11.44890414]]),
'class_log_prior_': array([-0.70223815, -0.68413811])}
We can predict on new articles and by transforming and then passing it to our classifierr.
article_vec = count_vec.transform(['this is about cryptography'])
clf.predict(article_vec)
array([1])
We can see that it was confident in that prediction:
clf.predict_proba(article_vec)
array([[0.00502949, 0.99497051]])
It would be high the other way with a different sentence:
article_vec = count_vec.transform(['this is about image processing'])
clf.predict(article_vec)
array([0])
If we make something about both topics, we can get less certain predictions:
article_vec = count_vec.transform(['this is about encrypting images'])
clf.predict_proba(article_vec)
array([[0.5753077, 0.4246923]])
24.4. TF-IDF#
This stands for term-frequency inverse document frequency. for a document number \(d\) and word number \(t\) with \(D\) total documents:
where: $\(\operatorname{idf}(t) = \log{\frac{1 + n}{1+\operatorname{df}(t)}} + 1\)$
and
\(\operatorname{df}(t)\) is the number of documents word \(t\) occurs in
\(\operatorname{tf(t,d)}\) is te number of times word \(t\) occurs in document \(d\)
then sklearn also normalizes as follows:
tfidf = text.TfidfTransformer()
ng_tfidf = tfidf.fit_transform(ng_vec)
24.5. Comparing representations#
Which representation is better?
To to this, we resplit the data so that the same sampls are in the test set for both representations:
ng_vec_train, ng_vec_test, ng_tfidf_train, ng_tfidf_test,ng_y_train, ng_y_test = train_test_split(ng_vec, ng_tfidf, ng_y)
Warning
In class, i used Multinomial NB for both and verbally said that was a bad choice because the TFIDF does not meet the assumptions it is not counts.
I have switched this to Gaussian.
Now we get two new classifiers
clf_vec = MultinomialNB()
clf_tfidf = GaussianNB()
and fit and score each
clf_vec.fit(ng_vec_train,ng_y_train).score(ng_vec_test,ng_y_test)
0.9898305084745763
clf_tfidf.fit(ng_tfidf_train,ng_y_train).score(ng_tfidf_test,ng_y_test)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[22], line 1
----> 1 clf_tfidf.fit(ng_tfidf_train,ng_y_train).score(ng_tfidf_test,ng_y_test)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/base.py:1152, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)
1145 estimator._validate_params()
1147 with config_context(
1148 skip_parameter_validation=(
1149 prefer_skip_nested_validation or global_skip_validation
1150 )
1151 ):
-> 1152 return fit_method(estimator, *args, **kwargs)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/naive_bayes.py:263, in GaussianNB.fit(self, X, y, sample_weight)
240 """Fit Gaussian Naive Bayes according to X, y.
241
242 Parameters
(...)
260 Returns the instance itself.
261 """
262 y = self._validate_data(y=y)
--> 263 return self._partial_fit(
264 X, y, np.unique(y), _refit=True, sample_weight=sample_weight
265 )
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/naive_bayes.py:423, in GaussianNB._partial_fit(self, X, y, classes, _refit, sample_weight)
420 self.classes_ = None
422 first_call = _check_partial_fit_first_call(self, classes)
--> 423 X, y = self._validate_data(X, y, reset=first_call)
424 if sample_weight is not None:
425 sample_weight = _check_sample_weight(sample_weight, X)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/base.py:622, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
620 y = check_array(y, input_name="y", **check_y_params)
621 else:
--> 622 X, y = check_X_y(X, y, **check_params)
623 out = X, y
625 if not no_val_X and check_params.get("ensure_2d", True):
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/utils/validation.py:1146, in check_X_y(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
1141 estimator_name = _check_estimator_name(estimator)
1142 raise ValueError(
1143 f"{estimator_name} requires y to be passed, but the target y is None"
1144 )
-> 1146 X = check_array(
1147 X,
1148 accept_sparse=accept_sparse,
1149 accept_large_sparse=accept_large_sparse,
1150 dtype=dtype,
1151 order=order,
1152 copy=copy,
1153 force_all_finite=force_all_finite,
1154 ensure_2d=ensure_2d,
1155 allow_nd=allow_nd,
1156 ensure_min_samples=ensure_min_samples,
1157 ensure_min_features=ensure_min_features,
1158 estimator=estimator,
1159 input_name="X",
1160 )
1162 y = _check_y(y, multi_output=multi_output, y_numeric=y_numeric, estimator=estimator)
1164 check_consistent_length(X, y)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/utils/validation.py:881, in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
879 if sp.issparse(array):
880 _ensure_no_complex_data(array)
--> 881 array = _ensure_sparse_format(
882 array,
883 accept_sparse=accept_sparse,
884 dtype=dtype,
885 copy=copy,
886 force_all_finite=force_all_finite,
887 accept_large_sparse=accept_large_sparse,
888 estimator_name=estimator_name,
889 input_name=input_name,
890 )
891 else:
892 # If np.array(..) gives ComplexWarning, then we convert the warning
893 # to an error. This is needed because specifying a non complex
894 # dtype to the function converts complex to real dtype,
895 # thereby passing the test made in the lines following the scope
896 # of warnings context manager.
897 with warnings.catch_warnings():
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/utils/validation.py:532, in _ensure_sparse_format(spmatrix, accept_sparse, dtype, copy, force_all_finite, accept_large_sparse, estimator_name, input_name)
529 _check_large_sparse(spmatrix, accept_large_sparse)
531 if accept_sparse is False:
--> 532 raise TypeError(
533 "A sparse matrix was passed, but dense "
534 "data is required. Use X.toarray() to "
535 "convert to a dense numpy array."
536 )
537 elif isinstance(accept_sparse, (list, tuple)):
538 if len(accept_sparse) == 0:
TypeError: A sparse matrix was passed, but dense data is required. Use X.toarray() to convert to a dense numpy array.
To get a more robust answer, we should use cross validation and likely use a different classifier. Multinomal Naive Bayes is well suited for the count data, but, strictly speaking, not the normalized ones.
24.6. Distances in Text Data#
ng_y[:20]
array([0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0])
selected_categories
['comp.graphics', 'sci.crypt']
Next we will take a few samples of each and see what the numerical representation gives us
first_graphics = np.where(ng_y == 0)[0]
first_crypt = np.where(ng_y == 1)[0]
where returns the indices where the condition is true
subset_rows = np.concatenate([first_graphics,first_crypt])
subset_rows
array([ 0, 1, 3, ..., 1174, 1176, 1178])
sns.heatmap( euclidean_distances(ng_tfidf[subset_rows]))
<Axes: >
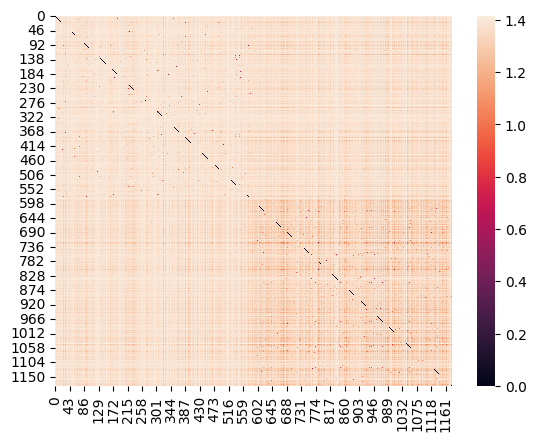
This shows that the graphics articles are close to one another, but the cryptography articles are far apart.
This mean thatt the graphics article are more similar to one another than they are to the cryptography articles. It also shows that the cryptography articles are more diverse than the graphics articles.
We could also look att only the test samples, but we can sort them
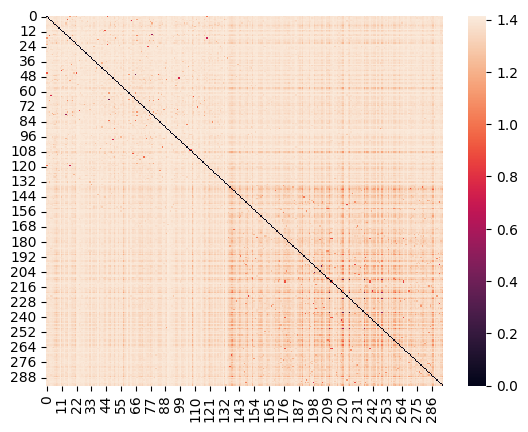
test_sorted = np.concatenate([np.where(ng_y_test == 0)[0],np.where(ng_y_test == 1)[0]])
sns.heatmap( euclidean_distances(ng_tfidf_test[test_sorted]))
<Axes: >
y_pred_tfidf = clf_tfidf.predict(ng_tfidf_test)
cols = pd.MultiIndex.from_arrays([['actual class']*len(selected_categories),
selected_categories])
rows = pd.MultiIndex.from_arrays([['predicted class']*len(selected_categories),
selected_categories])
pd.DataFrame(data = confusion_matrix(y_pred_tfidf,ng_y_test),columns = cols,
index = rows)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[29], line 1
----> 1 y_pred_tfidf = clf_tfidf.predict(ng_tfidf_test)
2 cols = pd.MultiIndex.from_arrays([['actual class']*len(selected_categories),
3 selected_categories])
4 rows = pd.MultiIndex.from_arrays([['predicted class']*len(selected_categories),
5 selected_categories])
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/naive_bayes.py:101, in _BaseNB.predict(self, X)
87 """
88 Perform classification on an array of test vectors X.
89
(...)
98 Predicted target values for X.
99 """
100 check_is_fitted(self)
--> 101 X = self._check_X(X)
102 jll = self._joint_log_likelihood(X)
103 return self.classes_[np.argmax(jll, axis=1)]
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/naive_bayes.py:269, in GaussianNB._check_X(self, X)
267 def _check_X(self, X):
268 """Validate X, used only in predict* methods."""
--> 269 return self._validate_data(X, reset=False)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/base.py:605, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
603 out = X, y
604 elif not no_val_X and no_val_y:
--> 605 out = check_array(X, input_name="X", **check_params)
606 elif no_val_X and not no_val_y:
607 out = _check_y(y, **check_params)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/utils/validation.py:881, in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
879 if sp.issparse(array):
880 _ensure_no_complex_data(array)
--> 881 array = _ensure_sparse_format(
882 array,
883 accept_sparse=accept_sparse,
884 dtype=dtype,
885 copy=copy,
886 force_all_finite=force_all_finite,
887 accept_large_sparse=accept_large_sparse,
888 estimator_name=estimator_name,
889 input_name=input_name,
890 )
891 else:
892 # If np.array(..) gives ComplexWarning, then we convert the warning
893 # to an error. This is needed because specifying a non complex
894 # dtype to the function converts complex to real dtype,
895 # thereby passing the test made in the lines following the scope
896 # of warnings context manager.
897 with warnings.catch_warnings():
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/sklearn/utils/validation.py:532, in _ensure_sparse_format(spmatrix, accept_sparse, dtype, copy, force_all_finite, accept_large_sparse, estimator_name, input_name)
529 _check_large_sparse(spmatrix, accept_large_sparse)
531 if accept_sparse is False:
--> 532 raise TypeError(
533 "A sparse matrix was passed, but dense "
534 "data is required. Use X.toarray() to "
535 "convert to a dense numpy array."
536 )
537 elif isinstance(accept_sparse, (list, tuple)):
538 if len(accept_sparse) == 0:
TypeError: A sparse matrix was passed, but dense data is required. Use X.toarray() to convert to a dense numpy array.
This makes sense that more of the errors are mislabeling computer graphics as cryptography, since the graphics articles are more diers and the cryptography articles were mostly similar to one another.