
1. Welcome and Introduction#
1.1. Prismia Chat#
We will use these to monitor your participation in class and to gather information. Features:
instructor only
reply to you directly
share responses for all
1.2. How this class will work#
Participatory Live Coding
What is a topic you want to use data to learn about?
1.3. Programming for Data Science vs other Programming#
The audience is different, so the form is different.
In Data Science our product is more often a report than a program.
Note
Also, in data science we are using code to interact with data, instead of having a plan in advance
So programming for data science is more like writing it has a narrative flow and is made to be seen more than some other programming thaat you may have done.
1.4. Jupyter Notebooks#
Launch a jupyter notebook server:
on Windows, use anaconda terminal
on Mac/Linux, use terminal
cd path/to/where/you/save/notes
jupyter notebook
1.4.1. What just happened?#
launched a local web server
opened a new browser tab pointed to it

1.4.2. Start a Notebook#
Go to the new menu in the top right and choose Python 3
Now, it starts a python kernel on the webserver

1.4.3. A jupyter notebook tour#
A Jupyter notebook has two modes. When you first open, it is in command mode. The border is blue in command mode.

When you press a key in command mode it works like a shortcut. For example p shows the command search menu.
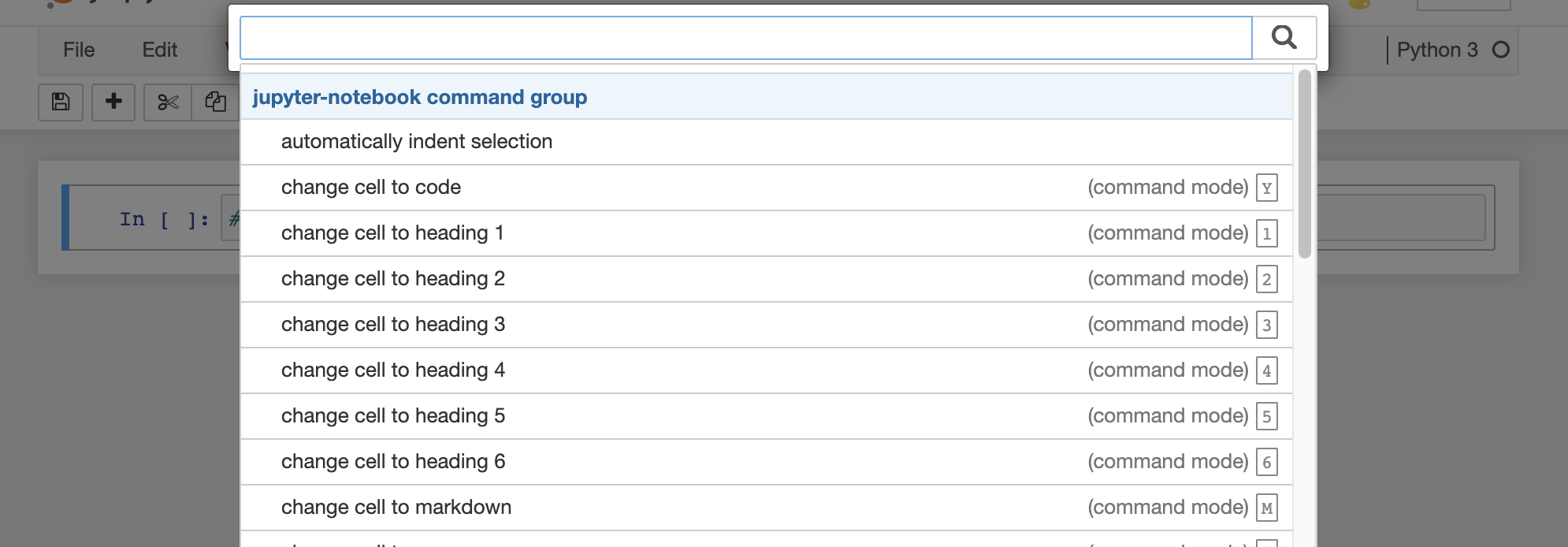
If you press enter (or return) or click on the highlighted cell, which is the boxes we can type in, it changes to edit mode. The border is green in edit mode

There are two type of cells that we will used: code and markdown. You can change that in command mode with y for code and m for markdown or on the cell type menu at the top of the notebook.
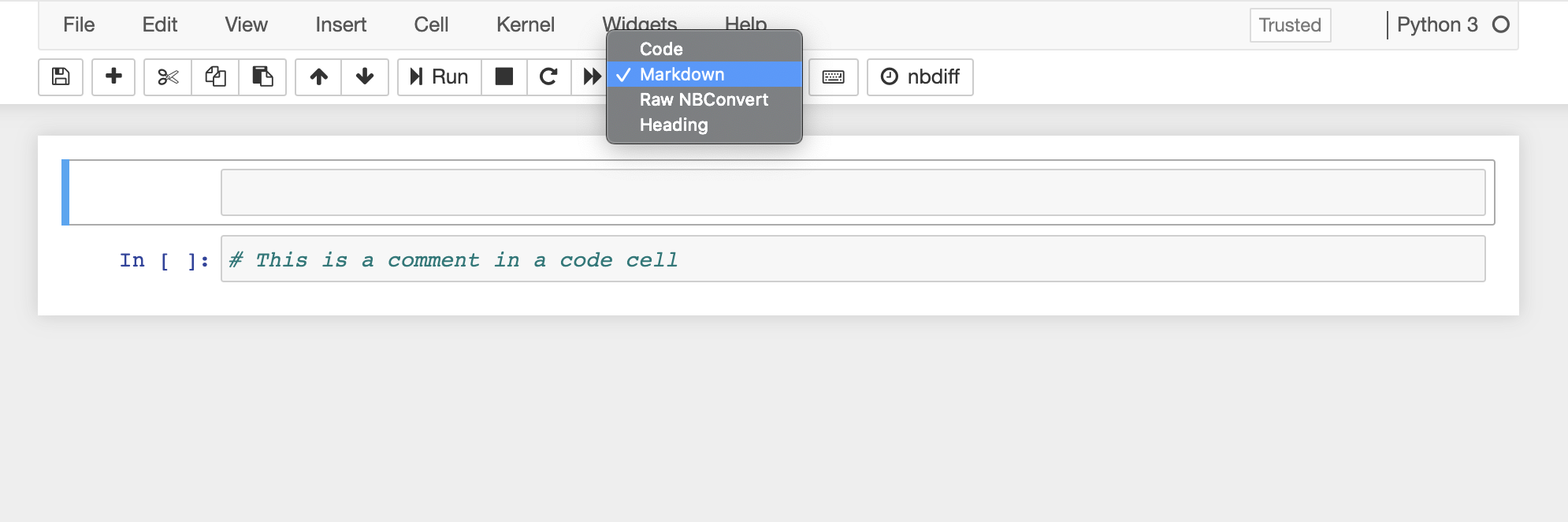
++
This is a markdown cell
we can make
itemized lists of
bullet points
and we can make nubmered
lists, and not have to worry
about renumbering them
if we add a step in the middle later
# this is a comment in a code cell , we can run this to see output
3+4
7
the output here is the value returned by the python interpretter for the last line of the cell
We set variables
name = 'sarah'
The notebook displays nothing when we do an assignment, bcause it returns nothing
name
'sarah'
we can put a variable there tosee it
course = 'csc310'
course
name
'sarah'
Note that this version doesn’t show use the value for course
name = 'Sarah'
Important
In class, we ran these cells out of order and noticed how the value does not update unless we run the new version
name
'Sarah'
course
'csc310'
1.4.4. Notebook Reminders#
Blue border is command mode, green border is edit mode
use Escape to get to command mode
Common command mode actions:
m: switch cell to markdown
y: switch cell to code
a: add a cell above
b: add a cell below
c: copy cell
v: paste the cell
0 + 0: restart kernel
p: command menu
use enter/return to get to edit mode
In code cells, we can use a python interpreter, for example as a calculator.
4+6
10
It prints out the last line of code that it ran, even though it executes all of them
name = 'sarah'
4+5
name *3
'sarahsarahsarah'
1.5. Getting Help in Jupyter#
Getting help is important in programming
When your cursor is inside the () of a function if you hold the shift key and press tab it will open a popup with information. If you press tab twice, it gets bigger and three times will make a popup window.
Python has a print function and we can use the help in jupyter to learn about
how to use it in different ways.
We can print the docstring out, as a whole instead of using the shfit + tab to view it.
help(print)
Help on built-in function print in module builtins:
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
The first line says that it can take multiple values, because it says value, ..., sep
It also has a
keyword argument (must be used like argument=value and has a default) described as sep=' '.
This means that by default it adds a space as above.
print(name)
sarah
How do you use the print function to output: Sarah_csc310?
print(name,course,sep='_')
sarah_csc310
help(print)
Help on built-in function print in module builtins:
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
We can put as many values as we want there. Thats what the ... in the function signature means
print(name,course,'hello','bye',sep='_')
sarah_csc310_hello_bye
print(name,course,'hello','bye',sep='\n')
sarah
csc310
hello
bye
Important
Basic programming is a prereq and we will go faster soon, but the goal of this review was to understand notebooks, getting help, and reading docstrings
1.6. What is Data Science?#
Data Science is the combination of
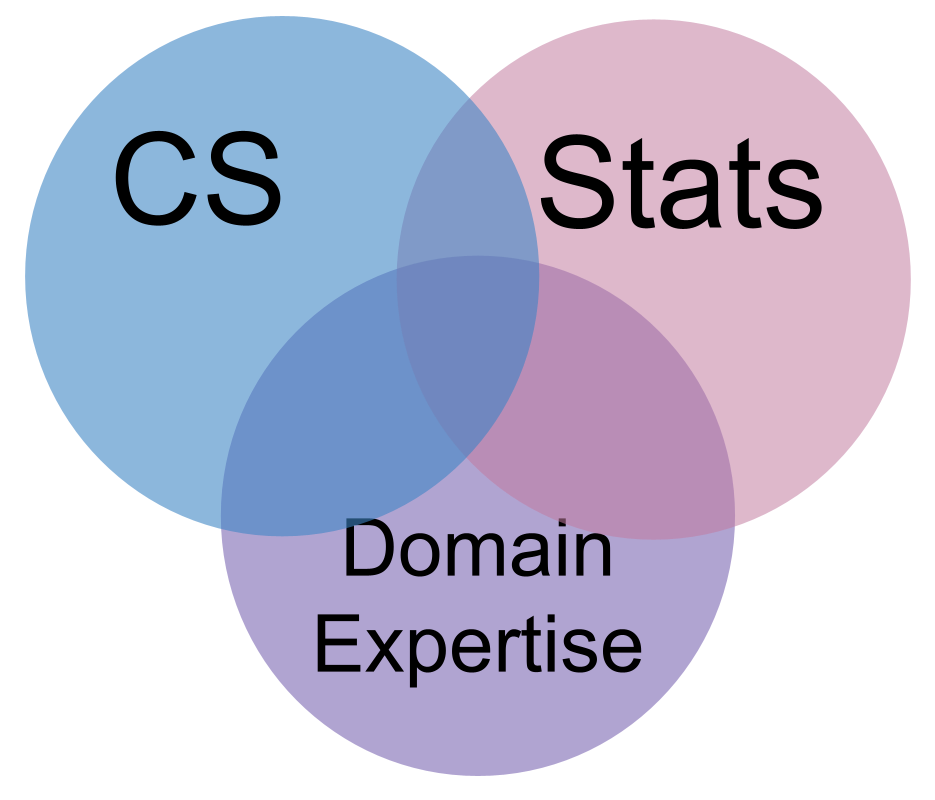
statistics is the type of math we use to make sense of data. Formally, a statistic is just a function of data.
computer science is so that we can manipulate visualize and automate the inferences we make.
domain expertise helps us have the intuition to know if what we did worked right. A statistic must be interpreted in context; the relevant context determines what they mean and which are valid. The context will say whether automating something is safe or not, it can help us tell whether our code actually worked right or not.
1.6.1. In this class,#
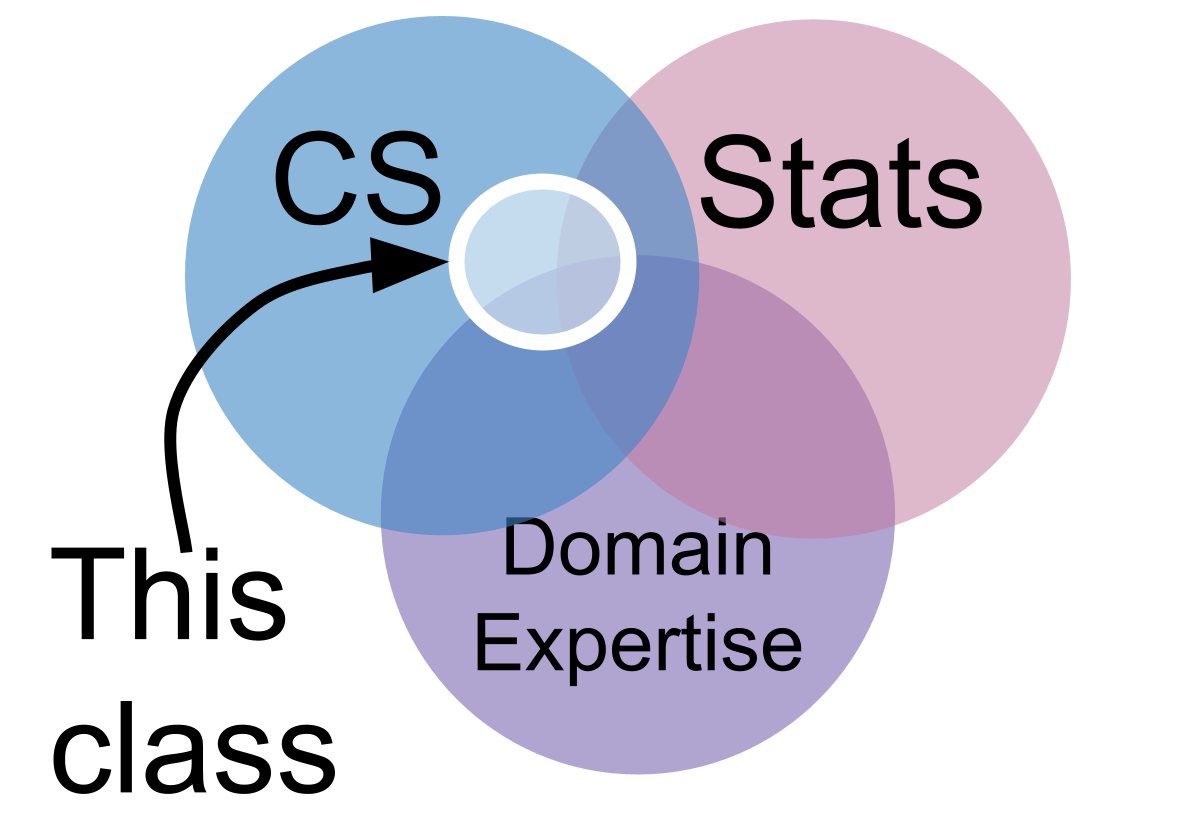
We’ll focus on the programming as our main means of studying data science, but we will use bits of the other parts. In particular, you’re encouraged to choose datasets that you have domain expertise about, or that you want to learn about.
But there are many definitions. We’ll use this one, but you may come across others.
1.6.2. How does data science happen?#
The most common way to think about what doing data science means is to think of this pipeline. It is in the perspective of the data, these are all of the things that happen to the data.

Another way to think about it

1.6.3. how we’ll cover Data Science, in depth#
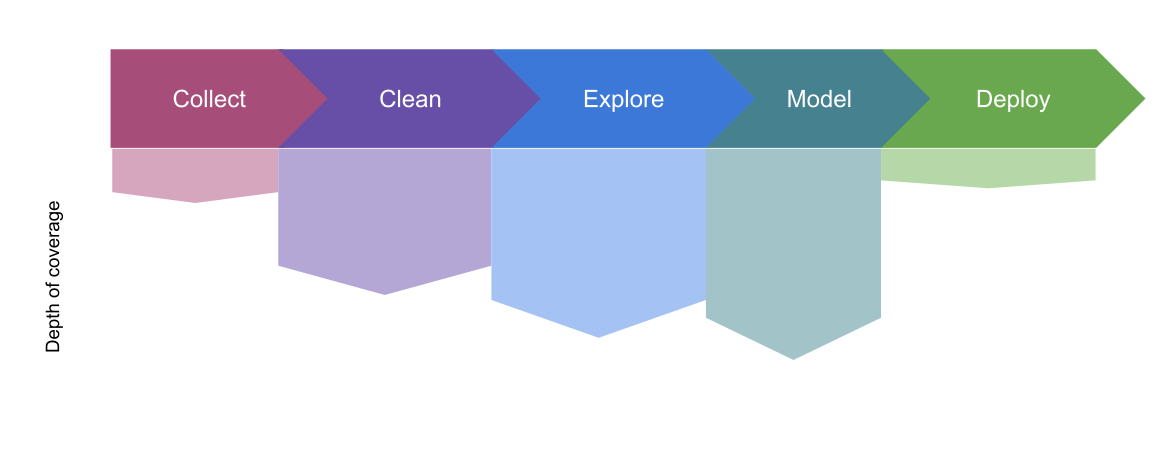
collect: Discuss only a little; Minimal programming involved
clean: Cover the main programming techniques; Some requires domain knowledge beyond scope of course
explore: Cover the main programming techniques; Some requires domain knowledge beyond scope of course
model:Cover the main programming, basic idea of models; How to use models, not how learning algorithms work
deploy: A little bit at the end, but a lot of preparation for decision making around deployment
1.6.4. how we’ll cover it in, time#
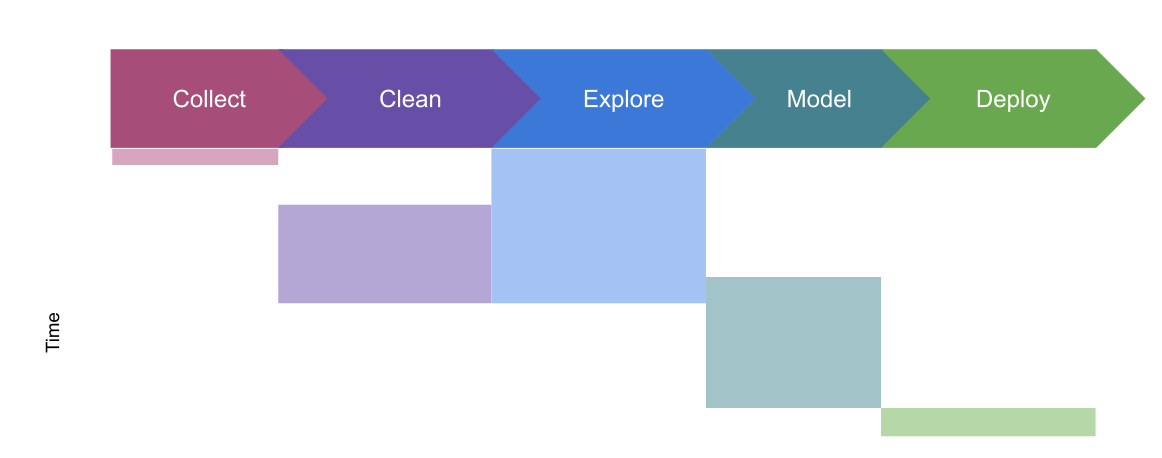
We’ll cover exploratory data analysis before cleaning because those tools will help us check how we’ve cleaned the data.
1.7. Prepare for the next class#
Read carefully the syllabus section of the course website
skim the rest of the course website
Bring questions about how the class will work to class on Thursday.
Review Git & GitHub Fundamentals
Bring git/github questions on Thursday.
Begin reading chapter 1 of think like a data scientist (finish in time for it to help you with the assignment due Monday night)
On Thursday we will start with a review of the syllabus. You will answer an ungraded quiz to confirm that you understand and I’ll answer all of your questions. Then we will do a little bit with Git/GitHub and start your first assignment in class.
Think like a data scientist is written for practitioners; not as a text book for a class. It does not have a lot of prerequisite background, but the sections of it that I assign will help you build a better mental picture of what doing Data Science about.
Warning
Only the first assignment will be due this fast, it’s a short review and setup assignment. It’s due quickly so that we know that you have everything set up and the prerequisite material before we start new material next week.