Class 27: Model Optimization- Choosing K¶
On the zoom chat, say hello
Log onto Prismia
# %load http://drsmb.co/310
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd
from sklearn import datasets
from sklearn import cluster
from sklearn import metrics
url ='https://raw.githubusercontent.com/rhodyprog4ds/06-naive-bayes/main/data/dataset2.csv'
df = pd.read_csv(url)
X = df.values[:,:-1]
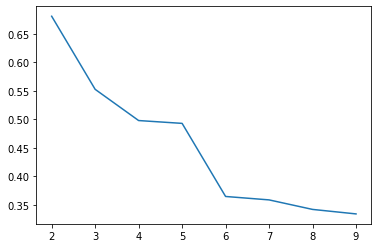
score = []
for k in range(2,10):
km = cluster.KMeans(n_clusters=k)
km.fit(X)
score.append(metrics.silhouette_score(X,km.labels_))
score
[0.6151956537579685,
0.5689398715407455,
0.5388658222509434,
0.5156765142705673,
0.4948750100931285,
0.47805666819267567,
0.45856852844475937,
0.4437858458538978]
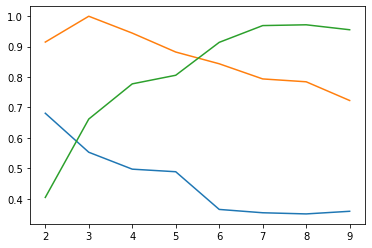
plt.plot(range(2,10), score)
[<matplotlib.lines.Line2D at 0x7fdea0059310>]
sns.pairplot(df)
<seaborn.axisgrid.PairGrid at 0x7fde9ffc1c10>
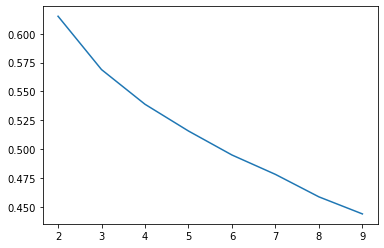
iris_X, _ = datasets.load_iris(return_X_y = True)
score_iris = []
for k in range(2,10):
km = cluster.KMeans(n_clusters=k)
km.fit(iris_X)
score_iris.append(metrics.silhouette_score(iris_X,km.labels_))
plt.plot(range(2,10), score_iris)
[<matplotlib.lines.Line2D at 0x7fde9ee967d0>]
silohette_iris = []
ch_iris = []
db_iris = []
for k in range(2,10):
km = cluster.KMeans(n_clusters=k)
km.fit(iris_X)
silohette_iris.append(metrics.silhouette_score(iris_X,km.labels_))
ch_iris.append(metrics.calinski_harabasz_score(iris_X,km.labels_))
db_iris.append(metrics.davies_bouldin_score(iris_X,km.labels_))
ch_iris = np.asarray(ch_iris)/np.max(ch_iris)
plt.plot(range(2,10), silohette_iris)
plt.plot(range(2,10), ch_iris)
plt.plot(range(2,10), db_iris)
[<matplotlib.lines.Line2D at 0x7fde9caaa9d0>]