
Midsemester feedback and Decision Trees
Contents
18. Midsemester feedback and Decision Trees#
import pandas as pd
import seaborn as sns
import numpy as np
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
sns.set(palette='colorblind')
18.1. Feedback#
Note
Analysis of the structured questions will be added
18.1.1. Key takeaways#
You’re learning and happy with how much you’re learning
You’ve noticed and appreciate that the assignments build on what we cover in class
You’re reading the notes & like them a lot
Assignment instructions are sometimes hard to understand
feedback_df_raw = pd.read_csv('data/mid_sem_feedback_struct.csv')
feedback_df_raw.head()
| How much do you think you've learned so far this semester? | How much of the material that's been taught do you feel you understand? | How do you think the achievements you've earned so far align with your understanding? | Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [How well I follow instructions] | Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [What I understand about the material] | Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [How much effort I put into assignments] | How fair do you think the amount each of the following is reflected in the grading [How well I follow instructions] | How fair do you think the amount each of the following is reflected in the grading [What I understand about the material] | How fair do you think the amount each of the following is reflected in the grading [How much effort I put into assignments] | Which of the following have you done to support your learning outside of class time? | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 4 | I think the achievements underestimate what I ... | Reflected strongly in the grading | Reflected moderately in the grading | Reflected perfectly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, reading the documentati... |
| 1 | 5 | 4 | I think they reflect my understanding well | Reflected strongly in the grading | Reflected perfectly in the grading | Reflected perfectly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, experimenting with the ... |
| 2 | 4 | 4 | I think they reflect my understanding well | Reflected strongly in the grading | Reflected strongly in the grading | Reflected strongly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, solving extra questions... |
| 3 | 3 | 3 | I think they reflect my understanding well | Reflected moderately in the grading | Reflected moderately in the grading | Reflected moderately in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, reading blogs or tutori... |
| 4 | 3 | 3 | I think the achievements overestimate what I k... | Reflected moderately in the grading | Reflected moderately in the grading | Reflected moderately in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, experimenting with the ... |
First, we’ll make the dataframe column names easier to work with and save a key of them as a dictionary that we then use to rename. First we look at them, then copy & paste them to make the dictionary.
feedback_df_raw.columns
Index(['How much do you think you've learned so far this semester?',
'How much of the material that's been taught do you feel you understand?',
'How do you think the achievements you've earned so far align with your understanding?',
'Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [How well I follow instructions]',
'Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [What I understand about the material]',
'Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [How much effort I put into assignments]',
'How fair do you think the amount each of the following is reflected in the grading [How well I follow instructions]',
'How fair do you think the amount each of the following is reflected in the grading [What I understand about the material]',
'How fair do you think the amount each of the following is reflected in the grading [How much effort I put into assignments]',
'Which of the following have you done to support your learning outside of class time?'],
dtype='object')
short_names = {"How much do you think you've learned so far this semester?":'learned',
"How much of the material that's been taught do you feel you understand?":'understand',
"How do you think the achievements you've earned so far align with your understanding?":'achievements',
'Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [How well I follow instructions]':'grading_instructions',
'Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [What I understand about the material]':'grading_understanding',
'Rank the following as what you feel the grading (when you do/not earn achievements) so far actually reflects about your performance in the class [How much effort I put into assignments]':'grading_effort',
'How fair do you think the amount each of the following is reflected in the grading [How well I follow instructions]':'fairness_instructions',
'How fair do you think the amount each of the following is reflected in the grading [What I understand about the material]':'fairness_understanding',
'How fair do you think the amount each of the following is reflected in the grading [How much effort I put into assignments]':'fairness_effort',
'Which of the following have you done to support your learning outside of class time?':'learning_activities'}
feedback_df_cols = feedback_df_raw.rename(columns = short_names)
feedback_df_cols.head()
| learned | understand | achievements | grading_instructions | grading_understanding | grading_effort | fairness_instructions | fairness_understanding | fairness_effort | learning_activities | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 4 | I think the achievements underestimate what I ... | Reflected strongly in the grading | Reflected moderately in the grading | Reflected perfectly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, reading the documentati... |
| 1 | 5 | 4 | I think they reflect my understanding well | Reflected strongly in the grading | Reflected perfectly in the grading | Reflected perfectly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, experimenting with the ... |
| 2 | 4 | 4 | I think they reflect my understanding well | Reflected strongly in the grading | Reflected strongly in the grading | Reflected strongly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, solving extra questions... |
| 3 | 3 | 3 | I think they reflect my understanding well | Reflected moderately in the grading | Reflected moderately in the grading | Reflected moderately in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, reading blogs or tutori... |
| 4 | 3 | 3 | I think the achievements overestimate what I k... | Reflected moderately in the grading | Reflected moderately in the grading | Reflected moderately in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, experimenting with the ... |
learning_lists = feedback_df_cols['learning_activities'].str.split(',')
learning_stacked = learning_lists.apply(pd.Series).stack()
learning_df = pd.get_dummies(learning_stacked).sum(level=0)
learning_df.head()
/tmp/ipykernel_2775/3116911913.py:3: FutureWarning: Using the level keyword in DataFrame and Series aggregations is deprecated and will be removed in a future version. Use groupby instead. df.sum(level=1) should use df.groupby(level=1).sum().
learning_df = pd.get_dummies(learning_stacked).sum(level=0)
| attended Chamudi's office hours | attended Dr. Brown's office hours | attended Dr. Brown's office hours | download and run the notes | experimenting with the code from class | reading blogs or tutorials I find on my own | reading the documentation or course text | solving extra questions in the class notes | tinkering with code to answer other aspects of the material that I'm curious about | update the notes I took during class time | watching videos that I find on my own | read the notes online | reading the documentation or course text | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
feedback_df = pd.concat([feedback_df_cols,learning_df])
feedback_df.head(2)
| learned | understand | achievements | grading_instructions | grading_understanding | grading_effort | fairness_instructions | fairness_understanding | fairness_effort | learning_activities | ... | download and run the notes | experimenting with the code from class | reading blogs or tutorials I find on my own | reading the documentation or course text | solving extra questions in the class notes | tinkering with code to answer other aspects of the material that I'm curious about | update the notes I took during class time | watching videos that I find on my own | read the notes online | reading the documentation or course text | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.0 | 4.0 | I think the achievements underestimate what I ... | Reflected strongly in the grading | Reflected moderately in the grading | Reflected perfectly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, reading the documentati... | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 5.0 | 4.0 | I think they reflect my understanding well | Reflected strongly in the grading | Reflected perfectly in the grading | Reflected perfectly in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | Is fairly reflected in the grading | read the notes online, experimenting with the ... | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
2 rows × 23 columns
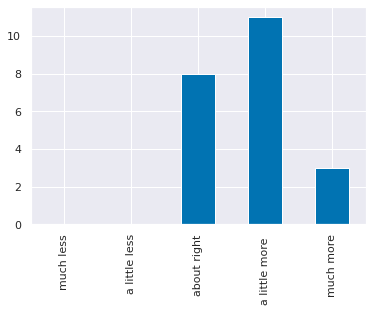
el_meaning = {1: 'much less',
2: 'a little less',
3: 'about right',
4: 'a little more ',
5: 'much more'}
question_text = list(short_names.keys())[list(short_names.values()).index('learned')]
el_counts,_ = np.histogram(feedback_df['learned'],bins = [i+.5 for i in range(6)])
el_df = pd.DataFrame(data = el_counts,index = el_meaning.values(),columns= [question_text],)
# el_df.rename_axis(index='amount relative to expectations',inplace=True)
el_df.plot.bar(legend=False);
# sns.displot(feedback_df['learned'].replace(el_meaning))
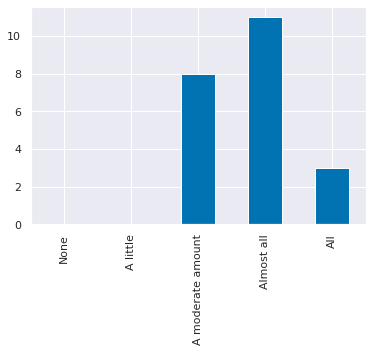
u_meaning = {0:'None', 1:'A little',3:'A moderate amount', 4:'Almost all',5:'All'}
question_text = list(short_names.keys())[list(short_names.values()).index('understand')]
u_counts,_ = np.histogram(feedback_df['understand'],bins = [i+.5 for i in range(6)])
u_df = pd.DataFrame(data = el_counts,index = u_meaning.values(),columns= [question_text],)
u_df.plot.bar(legend=False);
18.1.2. Reminders based on requests#
all deadlines are on the Brightspace calendar, you can sync that with your own calendar/scheduling tool
18.1.3. Changes going forward#
Assignments:
clarified instructions on assignments 7+ & a note to myself to fix assignments 1-5 for next year
a reminder when I post assignments to read before class Friday; time on Friday for clarifying questions
Chamudi & I will meet, re: grading consistency
regrade request policy posted on website
more advice on choosing a dataset and some possible good ones
will add “related notes” section
Some skill changes are coming, will be posted soon, to make more chances on a few skills
In class:
will continue working on remembering to send all of the code on prismia; feel free to post there to ask for it or raise your hand
will denote key things that will relate to assignments as much as possible
to make sure there’s space for questions at the end of class, I’ll use a google form exit ticket instead of prismia. I’ll still answer all of those questions in the notes, but it makes it easier to ask both pace & follow up. It will always be at: http://drsmb.co/310exit
Office hours:
I can change when but not how many hours per week, in particular no one has attended Tuesday afternoon, so I may move that.
:
18.1.4. Requests I will not fulfill#
regular in person office hours; by appointment only to ensure 1 person at a time
more total office hours
link directly where in the notes for assignments, part of the goal is for you to filter out the relevant parts from what we learn in a week in order to apply it. You can always ask questions in office hours though.
18.1.5. Notes#
this was anonymous, comments/updates/questions about grading specifically I cannot reply to; e-mail me if applicable
use this form to list issues with assignment text/ portfolio requirements to help me improve them in exchange for Ram Tokens
18.2. A6 data review#
a6_data = 'https://raw.githubusercontent.com/rhodyprog4ds/06-naive-bayes/f425ba121cc0c4dd8bcaa7ebb2ff0b40b0b03bff/data/dataset'
req_datasets = [1,2,5,6]
data_urls = [a6_data + str(i) +'.csv' for i in req_datasets]
[sns.pairplot(data =pd.read_csv(url,index_col=0), hue='char') for url in data_urls]
[<seaborn.axisgrid.PairGrid at 0x7fcfa86f4070>,
<seaborn.axisgrid.PairGrid at 0x7fcfa826f400>,
<seaborn.axisgrid.PairGrid at 0x7fcfaa81cd00>,
<seaborn.axisgrid.PairGrid at 0x7fcfa4ce5040>]
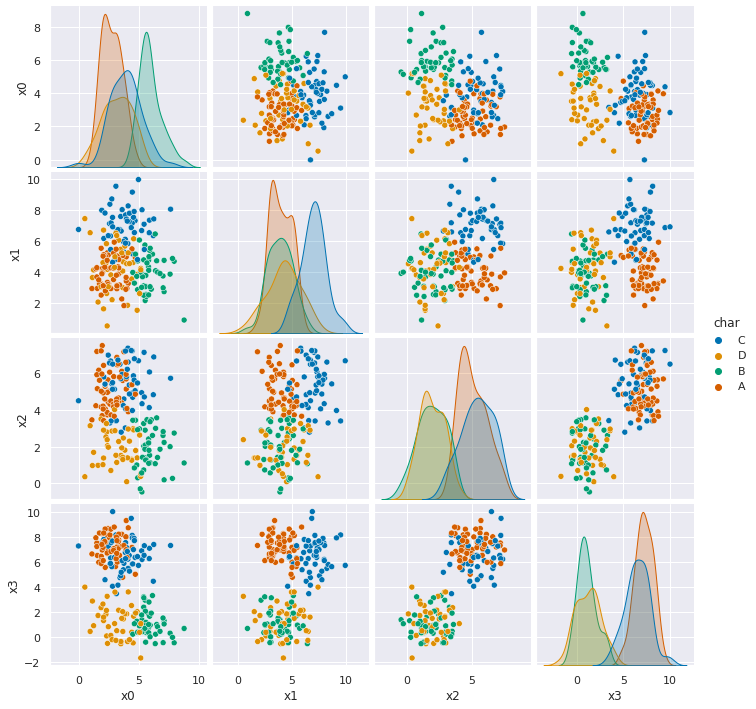
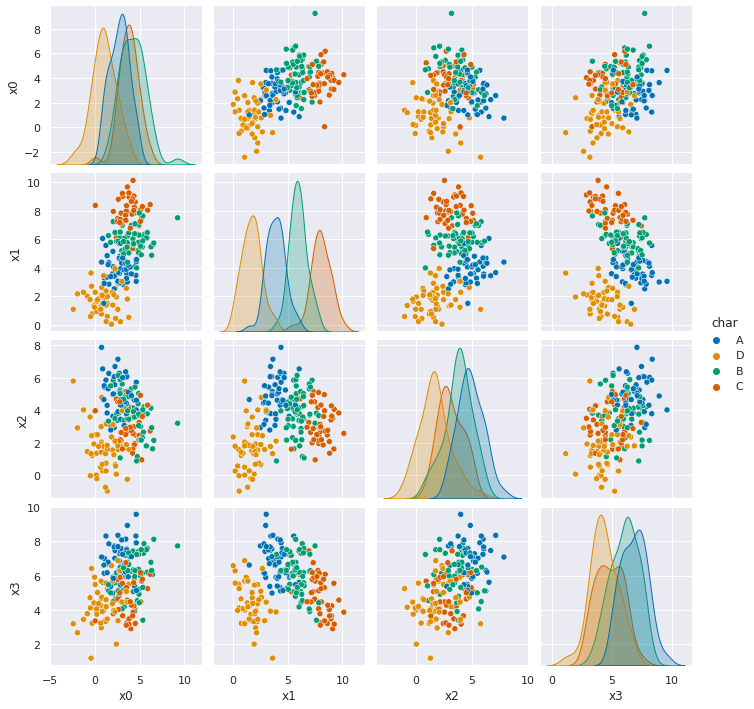
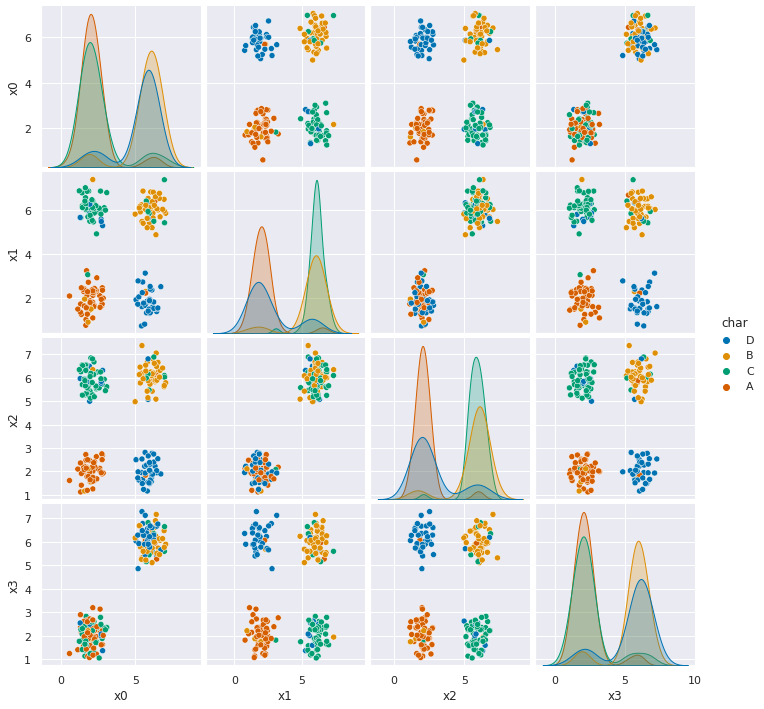
Dataset 1 & 2 it should perform reasonably well. They’re both Gaussian data, with some skew, but not too much and some overlap (more in 2).
Dataset 5, doesn’t do so well, but it’s performance is clearly because there’s some points in each group of points that are labeled differently than the others. This is to simulate the model for label bias which is one way that our traditional performance metrics can fool us. Our GNB classifier finds the four groups very reliably, but is “incorrect” on the points that are labeled differently. In real data this can occur in systematic ways, people from disadvantaged groups who otherwise may for example, qualify for a loan, have been denied historically. So, in training data they would be like the points in each group that are labeled differently.
Dataset 6, seems separable, but Guassian Naive Bayes gets about 50% accuracy.
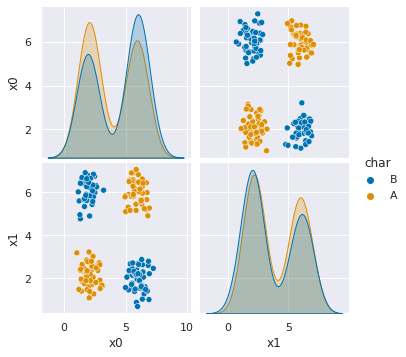
18.3. Let’s explore that last one…#
df6= pd.read_csv(data_urls[-1],usecols=[1,2,3])
sns.pairplot(data=df6, hue='char')
<seaborn.axisgrid.PairGrid at 0x7fcfa5caae80>
This data is separable even though the classifier we saw last week doesn’t work well for it, because not all of the points for each class are in a single blob. We could imagine a rule that would succeed: if ‘x0’ and ‘x1’ are both less than 4 or both more than 4, predict A otherwise predict B.
g = sns.JointGrid(data=df6, x='x0', y ='x1', hue='char')
g.plot_joint(sns.scatterplot)
g.plot_marginals(sns.kdeplot)
g.refline(x=4, y=4)
<seaborn.axisgrid.JointGrid at 0x7fcfa5bc82b0>
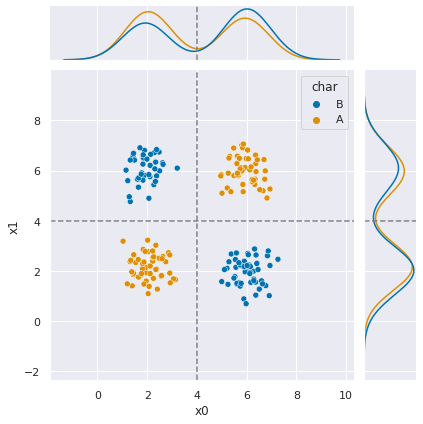
The dashed line here shows that those boundaries would separate the classes. I stated that rule in a single if, but we could also imagine it like a tree, a set of binary decisions.
18.4. Learning a Decision Tree#
We can learn a rule like this one from the data using a
DecisionTreeClassifier.
We’ll instantiate one from the tree module we imported from sklearn.
dt = tree.DecisionTreeClassifier()
As usual, we split the data into test and train and features and labels:
X_train, X_test, y_train, y_test = train_test_split(df6[['x0','x1']],
df6['char'],
random_state = 3094)
We fit it just like we fit the Gaussian Naive Bayes, using the fit method.
dt.fit(X_train,y_train)
DecisionTreeClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier()
18.5. Examining a Decision Tree#
Since decision trees have common functions whether they’re for regression or classification, the tree module provides some functions that we can use.
plt.figure(figsize=(15,20))
tree.plot_tree(dt, rounded =True, class_names = ['A','B'],
proportion=True, filled =True, impurity=False,fontsize=10)
[Text(0.6607142857142857, 0.9, 'X[0] <= 5.88\nsamples = 100.0%\nvalue = [0.493, 0.507]\nclass = B'),
Text(0.4642857142857143, 0.7, 'X[1] <= 5.325\nsamples = 70.7%\nvalue = [0.557, 0.443]\nclass = A'),
Text(0.2857142857142857, 0.5, 'X[0] <= 4.07\nsamples = 40.0%\nvalue = [0.733, 0.267]\nclass = A'),
Text(0.14285714285714285, 0.3, 'X[1] <= 3.98\nsamples = 28.7%\nvalue = [0.953, 0.047]\nclass = A'),
Text(0.07142857142857142, 0.1, 'samples = 27.3%\nvalue = [1.0, 0.0]\nclass = A'),
Text(0.21428571428571427, 0.1, 'samples = 1.3%\nvalue = [0.0, 1.0]\nclass = B'),
Text(0.42857142857142855, 0.3, 'X[1] <= 3.89\nsamples = 11.3%\nvalue = [0.176, 0.824]\nclass = B'),
Text(0.35714285714285715, 0.1, 'samples = 9.3%\nvalue = [0.0, 1.0]\nclass = B'),
Text(0.5, 0.1, 'samples = 2.0%\nvalue = [1.0, 0.0]\nclass = A'),
Text(0.6428571428571429, 0.5, 'X[0] <= 4.085\nsamples = 30.7%\nvalue = [0.326, 0.674]\nclass = B'),
Text(0.5714285714285714, 0.3, 'samples = 20.7%\nvalue = [0.0, 1.0]\nclass = B'),
Text(0.7142857142857143, 0.3, 'samples = 10.0%\nvalue = [1.0, 0.0]\nclass = A'),
Text(0.8571428571428571, 0.7, 'X[1] <= 3.805\nsamples = 29.3%\nvalue = [0.341, 0.659]\nclass = B'),
Text(0.7857142857142857, 0.5, 'samples = 19.3%\nvalue = [0.0, 1.0]\nclass = B'),
Text(0.9285714285714286, 0.5, 'samples = 10.0%\nvalue = [1.0, 0.0]\nclass = A')]
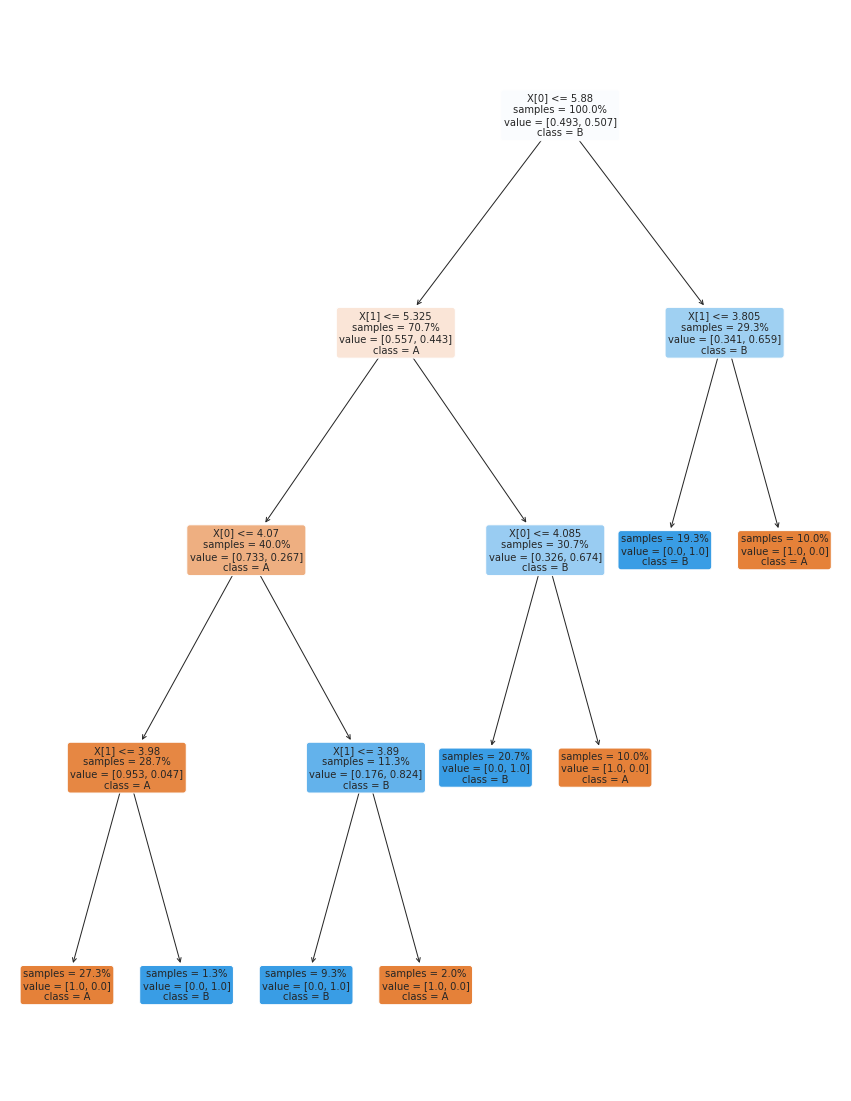
We can also get it out as text; since it returns a plain string, we’ll pass it through the print function.
print(tree.export_text(dt))
|--- feature_0 <= 5.88
| |--- feature_1 <= 5.33
| | |--- feature_0 <= 4.07
| | | |--- feature_1 <= 3.98
| | | | |--- class: A
| | | |--- feature_1 > 3.98
| | | | |--- class: B
| | |--- feature_0 > 4.07
| | | |--- feature_1 <= 3.89
| | | | |--- class: B
| | | |--- feature_1 > 3.89
| | | | |--- class: A
| |--- feature_1 > 5.33
| | |--- feature_0 <= 4.09
| | | |--- class: B
| | |--- feature_0 > 4.09
| | | |--- class: A
|--- feature_0 > 5.88
| |--- feature_1 <= 3.80
| | |--- class: B
| |--- feature_1 > 3.80
| | |--- class: A
this is the same tree as above.
Try it yourself
Take the time to match this representation to the one above. Read through the parts of the above and see how much it tells you
This tree is many more levels (it’s deeper) than the one we figured out by looking at the plotted data above. Before we experiment with changing that, let’s see how well it works.
dt.score(X_test,y_test)
1.0
It does well, but let’s see if we can change the depth and still do well?
18.6. Training parameters#
For the Gaussian Naive Bayes classifier, we didn’t change how it trained at all. It’s a simple classifer, so it’s not as impactful. Since Decision Trees are more complex, the model has hyper parameters and the training algorithm (fit method) has parameters.
With sklearn these parameters are set when the object is instantiated. We’ll see more on Friday, but for now, we’ll set the max_depth.
dt2 = tree.DecisionTreeClassifier(max_depth=2)
dt2.fit(X_train,y_train)
dt2.score(X_test,y_test)
0.74
print(tree.export_text(dt2))
|--- feature_0 <= 5.88
| |--- feature_1 <= 5.33
| | |--- class: A
| |--- feature_1 > 5.33
| | |--- class: B
|--- feature_0 > 5.88
| |--- feature_1 <= 3.80
| | |--- class: B
| |--- feature_1 > 3.80
| | |--- class: A
18.7. Questions After Class#
18.7.1. What is it best used on?#
Decision trees are good for lots of tabular data (not images).
18.7.2. Is there a maximum amount of branches for a tree#
A tree will always have binary splits, so the maximum number of leaf nodes (ends) is the size of the data. That wouldn’t be a very good classifer though, we’ll see Friday we can make the size needed to split the data (create a new branch) larger as another way to control the tree.
18.7.3. Why do the decision trees work for some data but not others.#
Varialbe performance is due to the data and
18.7.4. What could we really use these trees for?#
Decision trees are a very widely used algorithm for making predictions. In fact, a flowchart of this form is used in some contexts even when not learned from data.
18.7.5. How is the tree created?#
We’ll talk about this a little bit on Friday, but it’s mostly out of scope for this course. It is something you could learn about independently for your portfolio, or it will be covered in depth in CSC461.
The sklearn docs include a whole algoithms section that describes everything including their history and detailed mathematical formulation.
18.7.6. Do I use a gnb when I know the distribution is gaussian?#
Yes, or at least close enough. Fitting the model to the data is a good practice. We’ll learn about overfitting soon and by matching, you’re less likely to face this problem.