
Model Optimization
Contents
32. Model Optimization#
Important
Remember that best is context dependent and relative. The best accuracy might not be the best overall. Automatic optimization can only find the best thing in terms of a single score.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd
from sklearn import datasets
from sklearn import cluster
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn import tree
32.1. Model validation#
We will work with the iris data again.
iris_df = sns.load_dataset('iris')
iris_X = iris_df.drop(columns=['species'])
iris_y = iris_df['species']
We will still use the test train split to keep our test data separate from the data that we use to find our preferred parameters.
iris_X_train, iris_X_test, iris_y_train, iris_y_test = train_test_split(iris_X,iris_y,
random_state=0)
Today we will optimize a decision tree over three parameters. One is the criterion, which is how it decides where to create thresholds in parameters. Gini is the default and it computes how concentrated each class is at that node, another is entropy, entropy is, generally how random something is. Intuitively these do similar things, which makes sense because they are two ways to make the same choice, but they have slightly different calculations.
The other two parameters we have seen some before. Max depth is the height of the tree and min smaples per leaf makes it keeps the leaf sizes small.
dt = tree.DecisionTreeClassifier()
params_dt = {'criterion':['gini','entropy'],'max_depth':[2,3,4],
'min_samples_leaf':list(range(2,20,2))}
We will fit it with default CV settings.
dt_opt = GridSearchCV(dt,params_dt)
then we can fit
dt_opt.fit(iris_X_train,iris_y_train)
GridSearchCV(estimator=DecisionTreeClassifier(),
param_grid={'criterion': ['gini', 'entropy'],
'max_depth': [2, 3, 4],
'min_samples_leaf': [2, 4, 6, 8, 10, 12, 14, 16, 18]})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(estimator=DecisionTreeClassifier(),
param_grid={'criterion': ['gini', 'entropy'],
'max_depth': [2, 3, 4],
'min_samples_leaf': [2, 4, 6, 8, 10, 12, 14, 16, 18]})DecisionTreeClassifier()
DecisionTreeClassifier()
we can use ti to get predictions
y_pred = dt_opt.predict(iris_X_test)
we can also score it as regular.
dt_opt.score(iris_X_test,iris_y_test)
0.9473684210526315
we can also see the best parameters.
dt_opt.best_params_
{'criterion': 'gini', 'max_depth': 4, 'min_samples_leaf': 2}
we can look at the overall results this way:
dt_5cv_df = pd.DataFrame(dt_opt.cv_results_)
dt_5cv_df.head()
| mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_criterion | param_max_depth | param_min_samples_leaf | params | split0_test_score | split1_test_score | split2_test_score | split3_test_score | split4_test_score | mean_test_score | std_test_score | rank_test_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.001978 | 0.000329 | 0.001265 | 0.000093 | gini | 2 | 2 | {'criterion': 'gini', 'max_depth': 2, 'min_sam... | 0.956522 | 0.913043 | 1.0 | 0.909091 | 0.954545 | 0.94664 | 0.033305 | 5 |
| 1 | 0.001773 | 0.000014 | 0.001268 | 0.000166 | gini | 2 | 4 | {'criterion': 'gini', 'max_depth': 2, 'min_sam... | 0.956522 | 0.913043 | 1.0 | 0.909091 | 0.954545 | 0.94664 | 0.033305 | 5 |
| 2 | 0.001752 | 0.000022 | 0.001200 | 0.000043 | gini | 2 | 6 | {'criterion': 'gini', 'max_depth': 2, 'min_sam... | 0.956522 | 0.913043 | 1.0 | 0.909091 | 0.954545 | 0.94664 | 0.033305 | 5 |
| 3 | 0.001747 | 0.000019 | 0.001199 | 0.000019 | gini | 2 | 8 | {'criterion': 'gini', 'max_depth': 2, 'min_sam... | 0.956522 | 0.913043 | 1.0 | 0.909091 | 0.954545 | 0.94664 | 0.033305 | 5 |
| 4 | 0.001736 | 0.000030 | 0.001188 | 0.000019 | gini | 2 | 10 | {'criterion': 'gini', 'max_depth': 2, 'min_sam... | 0.956522 | 0.913043 | 1.0 | 0.909091 | 0.954545 | 0.94664 | 0.033305 | 5 |
To see more carefully what it does, we can look at its shape.
dt_5cv_df.shape
(54, 16)
we can see that the total number of rows matched the product of the length of each list of parameters to try.
np.product([len(param_list) for param_list in params_dt.values()])
54
This means that it tests every combination of features– without us writing a bunch of nested loops.
We can also plot the dta and look at the performance.
sns.catplot(data=dt_5cv_df,x='param_min_samples_leaf',y='mean_test_score',
col='param_criterion', row= 'param_max_depth', kind='bar',)
<seaborn.axisgrid.FacetGrid at 0x7ff1a099adc0>
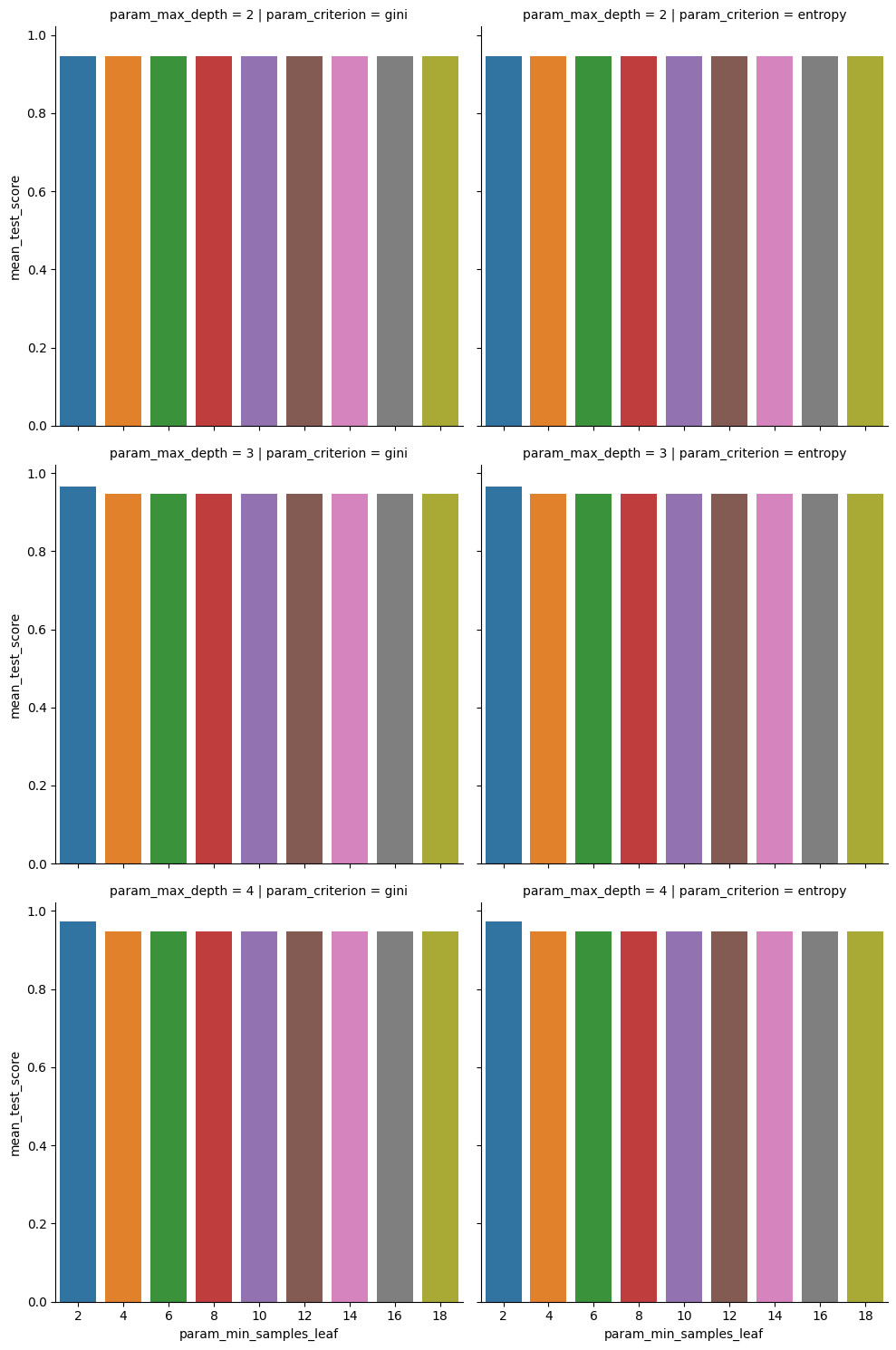
this makes it clear that none of these stick out much in terms of performance.
32.2. Impact of CV parameters#
dt_opt10 = GridSearchCV(dt,params_dt,cv=10)
dt_opt10.fit(iris_X_train,iris_y_train)
GridSearchCV(cv=10, estimator=DecisionTreeClassifier(),
param_grid={'criterion': ['gini', 'entropy'],
'max_depth': [2, 3, 4],
'min_samples_leaf': [2, 4, 6, 8, 10, 12, 14, 16, 18]})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=10, estimator=DecisionTreeClassifier(),
param_grid={'criterion': ['gini', 'entropy'],
'max_depth': [2, 3, 4],
'min_samples_leaf': [2, 4, 6, 8, 10, 12, 14, 16, 18]})DecisionTreeClassifier()
DecisionTreeClassifier()
dt_10cv_df = pd.DataFrame(dt_opt10.cv_results_)
We can stack the columns we want from the two results together with a new indicator column cv
plot_cols = ['param_min_samples_leaf','std_test_score','mean_test_score',
'param_criterion','param_max_depth','cv']
dt_10cv_df['cv'] = 10
dt_5cv_df['cv'] = 5
dt_cv_df = pd.concat([dt_5cv_df[plot_cols],dt_10cv_df[plot_cols]])
dt_cv_df.head()
| param_min_samples_leaf | std_test_score | mean_test_score | param_criterion | param_max_depth | cv | |
|---|---|---|---|---|---|---|
| 0 | 2 | 0.033305 | 0.94664 | gini | 2 | 5 |
| 1 | 4 | 0.033305 | 0.94664 | gini | 2 | 5 |
| 2 | 6 | 0.033305 | 0.94664 | gini | 2 | 5 |
| 3 | 8 | 0.033305 | 0.94664 | gini | 2 | 5 |
| 4 | 10 | 0.033305 | 0.94664 | gini | 2 | 5 |
this can be used to plot.
sns.catplot(data=dt_cv_df,x='param_min_samples_leaf',y='mean_test_score',
col='param_criterion', row= 'param_max_depth', kind='bar',
hue = 'cv')
<seaborn.axisgrid.FacetGrid at 0x7ff1dd8025e0>
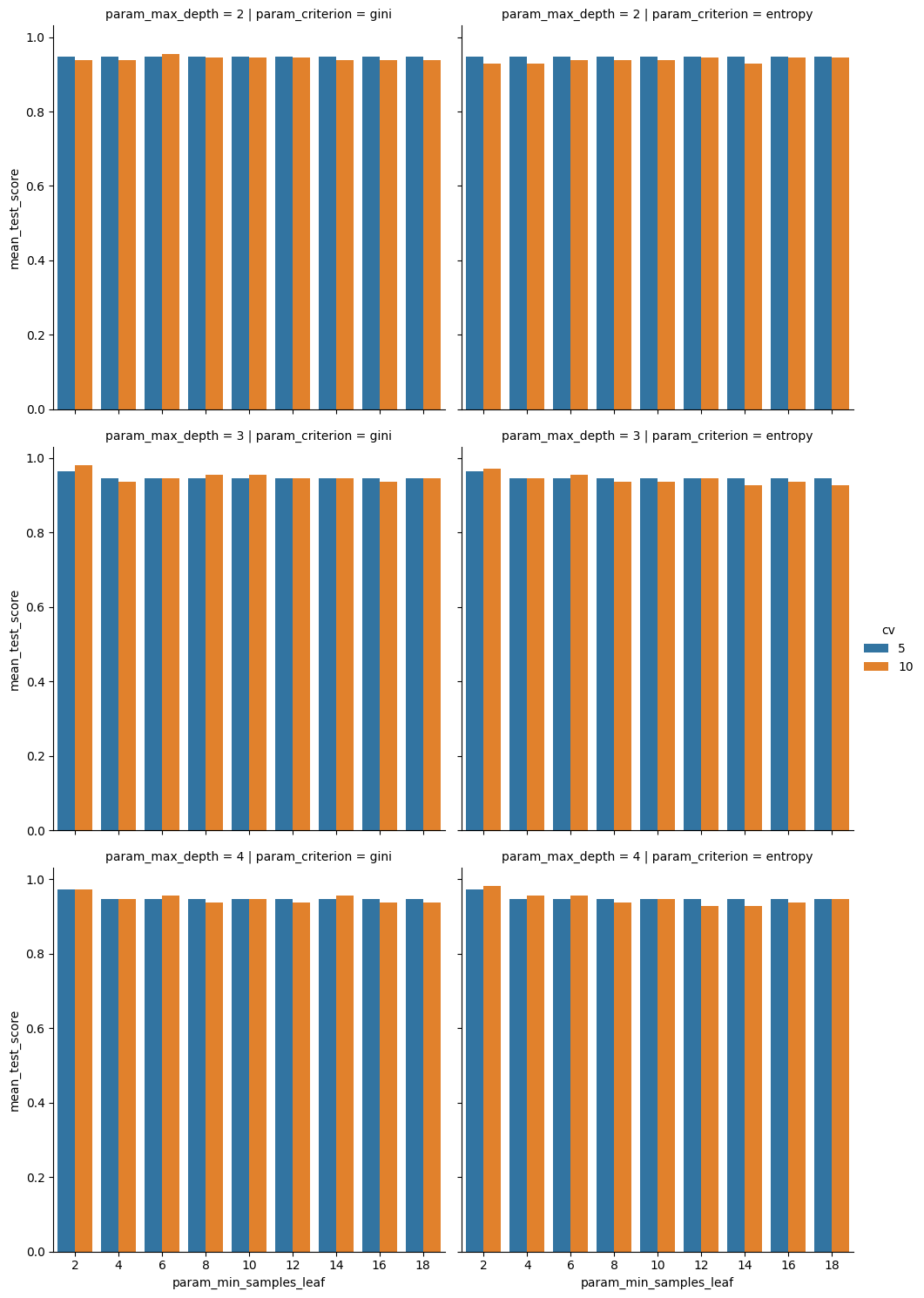
we see that the mean scores are not very different, but that 10 is a little higher in some cases. This makes sense, it has more data to learn from, so it found something that applied better, on average, to the test set.
sns.catplot(data=dt_cv_df,x='param_min_samples_leaf',y='std_test_score',
col='param_criterion', row= 'param_max_depth', kind='bar',
hue = 'cv')
<seaborn.axisgrid.FacetGrid at 0x7ff1a02696a0>
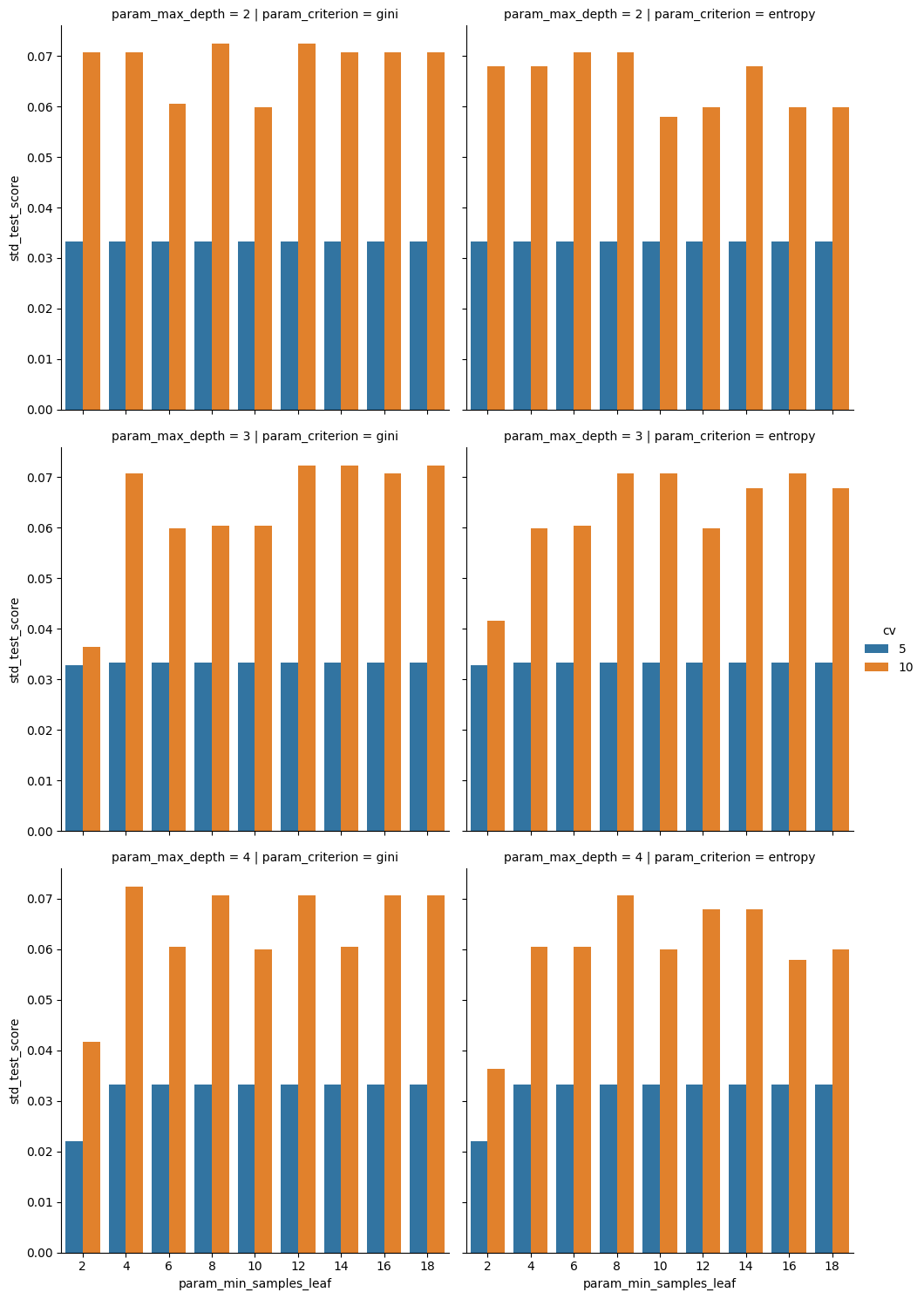
However here we see that the variabilty in those scores is much higher, so maybe the 5 is better.
We can compare to see if it finds the same model as best:
dt_opt.best_params_
{'criterion': 'gini', 'max_depth': 4, 'min_samples_leaf': 2}
dt_opt10.best_params_
{'criterion': 'gini', 'max_depth': 3, 'min_samples_leaf': 2}
In some cases they will and others they will not.
dt_opt.score(iris_X_test,iris_y_test)
0.9473684210526315
dt_opt10.score(iris_X_test,iris_y_test)
0.9736842105263158
In some cases they will find the same model and score the same, but it other time they will not.
The takeaway is that the cross validation parameters impact our ability to measure the score and possibly how close that cross validation mean score will match the true test score. Mostly it will change the variability in the estimate of the score. It does not change necessarily which model is best, that is up to the data iteself (the original test/train split would impact this).
Try it yourself
Does this vary if you repeat this with different test sets? How much does it depend on that? Does repeating it produce the same scores? Does one take longer to fit or score?
32.3. Other searches#
from sklearn import model_selection
from sklearn.model_selection import LeaveOneOut
rand_opt = model_selection.RandomizedSearchCV(dt,params_dt).fit(iris_X_train,
iris_y_train)
rand_opt.score(iris_X_test,iris_y_test)
0.9736842105263158
rand_opt.best_params_
{'min_samples_leaf': 2, 'max_depth': 3, 'criterion': 'entropy'}
It might find the same solution, but it also might not. If you do some and see that the parameters overall do not impact the scores much, then you can trust whichever one, or consider other criteria to choose the best model to use.
32.4. Questions after class#
32.4.1. What does cross-validation do that clustering doesn’t?#
Cross validation can be used with clustering if you want. Cross validation is a technique for evaluating how well a model performs; in this case we are combining with a search to find the best parameters.
32.4.2. Is grid search commonly used or is it too expensive for more realistically sized datasets?#
Grid search is realistic for simple models. It becomes more expensive with models that have more options for parameters. For example a parameter that can be continuously valued or take a large range, there become too many to test, so we use the random search or something else. The cost does go up some with larger datasets, but this scales primarily with the nubmer of parameters and values for each.
For example, bayesian optimization is a more complex type of random search.
32.4.3. What is the difference between gini and entropy?#
the criteria are discussed in the mathematical formulation of the sklearn documentation
32.4.4. Is it more accurate to do cross vaididation or test_train_split?#
Ideally both: use train test split to set aside a test set for the value that you will report when you say this is how good my final model is and cross validation to choose which model you call the final model.